What is Entity Resolution?
Entity resolution, also known as record linkage or deduplication, is a process in data management and data analysis where records that correspond to the same entity across different data sources or within the same dataset are identified and associated. The goal of entity resolution is to link or merge these records accurately, creating a consolidated and accurate view of the underlying entities.
Table of Contents
In practical terms, entity resolution deals with the challenge of dealing with duplicate or similar records in a dataset, which may arise due to various factors such as data entry errors, inconsistencies, or multiple data sources. This process is crucial for ensuring data quality, improving the accuracy of analytics and decision-making, and maintaining a unified and coherent representation of entities within a database.
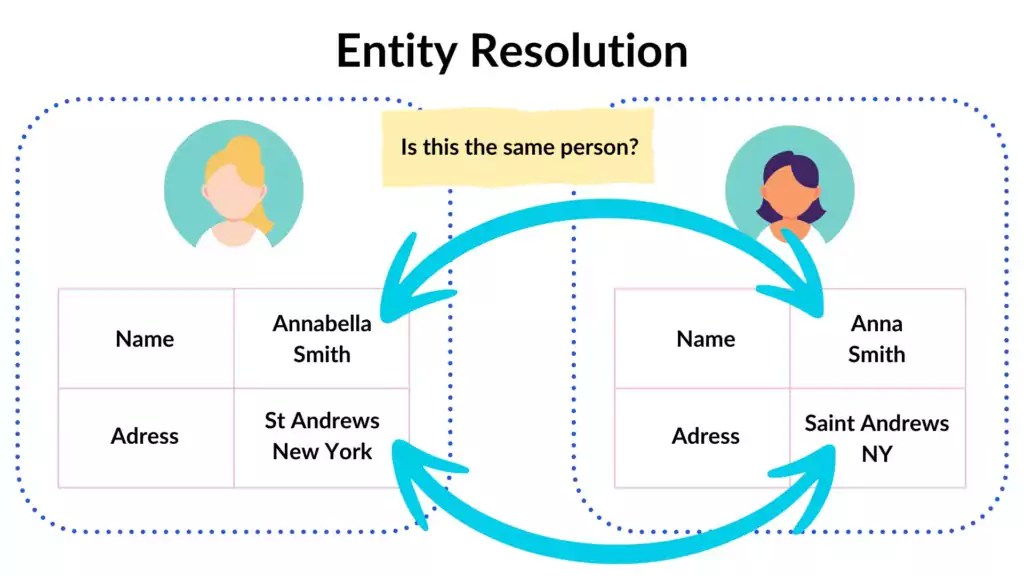
Entity resolution involves several key components and steps, including:
- Entities: The real-world objects or individuals that the records represent. For example, entities could be customers, patients, products, or other objects of interest.
- Records: The individual data entries or instances that pertain to a specific entity. Records may come from different sources and may have variations in their representation.
- Duplicate Detection: The identification of records that refer to the same entity. This often involves comparing records based on various attributes and determining a level of similarity.
- Matching Algorithms: The rules or algorithms used to compare records and determine their similarity or dissimilarity. Matching algorithms can be deterministic, probabilistic, rule-based, or machine learning-based.
- Resolution: The process of merging or linking the identified duplicates to create a single, consolidated representation of the entity. This step may involve updating, deleting, or combining records.
Entity resolution is critical in various domains, including customer relationship management, healthcare, finance, and other fields where maintaining accurate and consistent data is essential. It helps organizations avoid errors, reduce redundancy, and ensure their data is reliable for analytical and operational purposes.
12 Different Entity Resolution Techniques
Entity Resolution techniques encompass a variety of approaches aimed at accurately identifying and linking records corresponding to the same real-world entities. These techniques can be broadly categorized into different methods, each with strengths and suitable use cases.

Here are some common techniques:
Deterministic Matching Techniques
1. Exact Matching
The simplest form of matching is where records are linked if they share identical values in specific attributes. It is effective for datasets with clean and standardized data.
2. Phonetic Matching
Matches records based on the phonetic similarity of names or other textual data. Standard algorithms include Soundex or Metaphone, which encode words based on their pronunciation.
3. Token-based Matching
It involves breaking text into tokens (words or phrases) and comparing the sets of tokens between records. Jaccard similarity or cosine similarity metrics are often used for this purpose.
Probabilistic Matching Techniques
4. Fellegi-Sunter Model
Assign probabilities to potential matches by considering agreement and disagreement on attribute values. It allows for handling uncertainty in matching and is widely used in probabilistic record linkage.
Measures the similarity between sets of elements. Applied to attributes represented assets (e.g., words in a document), it helps identify matching records based on the overlap of elements.
6. Blocking and Windowing
Divide the dataset into blocks or windows based on specific criteria, reducing the number of record pairs to compare. This can significantly improve computational efficiency.
Machine Learning-based Techniques
It involves creating relevant features that capture the similarity between records. Features may include token frequencies, string similarities, or domain-specific attributes.
Trains models on labelled datasets to predict whether pairs of records represent the same entity. Standard algorithms include Support Vector Machines (SVM) and Random Forests.
Utilizes clustering algorithms to group similar records. Hierarchical Clustering, K-means, and DBSCAN are examples of unsupervised approaches.
Neural network architectures, such as Siamese Networks or recurrent neural networks (RNNs), can be employed for learning complex patterns in textual or structural data for entity resolution.
Rule-based Matching
11. Custom Rules and Thresholds
Define specific rules and thresholds for matching based on domain knowledge. This approach allows for high customization and adaptability to different datasets.
12. Transitive Closure
Applies transitive rules to infer matches indirectly. If A matches with B and B matches with C, it infers that A matches with C.
These techniques can be used individually or in combination, depending on the characteristics of the data and the requirements of the entity resolution task at hand. Selecting the most appropriate technique often involves considering factors like data quality, entities’ nature, and the available computational resources.
Named Entity Resolution
Named Entity Resolution (NER), or Named Entity Recognition, is a subset of entity resolution that focuses on identifying and classifying named entities within text data. Named entities are words or phrases that refer to specific, predefined categories such as names of people, organizations, locations, dates, and other entities of interest.
The primary goal of Named Entity Resolution is to extract and classify these entities from unstructured text, making it possible to analyze and understand the information contained within the text more effectively. This process involves identifying the boundaries of named entities and assigning them to predefined categories.

A sentence tagged with named entities.
Key components include:
- Named Entity Types:
- Person: Names of individuals.
- Organization: Names of companies, institutions, or other organized groups.
- Location: Geographic locations, such as cities, countries, or landmarks.
- Date: Specific dates or time expressions.
- Time: Specific times or time intervals.
- Percentage: Percentage expressions.
- Money: Monetary expressions.
- Miscellaneous: Other named entities do not fall into the above categories.
- Tokenization and Segmentation:
- Breaking down the input text into individual tokens (words or phrases) and identifying the boundaries of named entities.
- Classification:
- Assigning each identified token to a specific named entity type based on predefined categories.
- Contextual Disambiguation:
- Resolving cases where a term may have multiple possible interpretations based on the surrounding context.
- Machine Learning and Rule-based Approaches:
- Named Entity Resolution can be approached using machine learning models, rule-based systems, or a combination. Machine learning models may use features such as word embeddings, context, and syntactic information to classify named entities.
Applications of Named Entity Resolution include:
- Information Extraction: Extracting structured information from unstructured text.
- Question Answering Systems: Enhancing the ability to answer questions by understanding entities mentioned in the queries.
- Document Summarization: Improving the summarization of documents by identifying key entities.
- Search Engines: Enhancing search results by recognizing and categorizing named entities in documents.
Named Entity Resolution is a fundamental component in natural language processing and text mining, playing a crucial role in transforming unstructured text data into a structured and analyzable format.
Challenges in Entity Resolution
While Entity Resolution is a crucial process for maintaining data integrity and consistency, it comes with challenges that organizations must address to ensure accurate and reliable results. Here are some of the critical challenges faced in Entity Resolution:
- Data Quality Issues
- Inconsistencies: Variations in data formats, representations, or units across different sources can lead to difficulty identifying and matching entities.
- Missing Data: Incomplete or missing information in records can hinder the matching process, as critical attributes required for resolution may be absent.
- Data Errors: Data entry errors, typographical mistakes, or inaccuracies in source systems can introduce noise, making it difficult to identify accurate matches.
- Scalability Challenges
- Handling Large Datasets: As datasets grow in size, the computational complexity of entity resolution increases. Efficient algorithms and scalable solutions are required to process vast amounts of data.
- Performance Considerations: Real-time or near-real-time entity resolution in high-throughput environments poses performance challenges. Balancing accuracy with computational efficiency becomes crucial.
- Privacy and Security Concerns
- Protecting Sensitive Information: Entity Resolution often involves comparing and linking sensitive data records. Ensuring the privacy and security of such information is paramount to comply with regulations and safeguard individual privacy.
- Compliance with Data Regulations: Adhering to data protection regulations like GDPR or HIPAA while performing entity resolution adds complexity. Organizations must implement practices that balance the need for accurate matching with regulatory compliance.

Addressing these challenges requires a holistic approach that combines advanced algorithms, data preprocessing techniques, and adherence to privacy regulations. Overcoming these hurdles is essential to unlock the full potential of entity resolution in enhancing data quality and supporting reliable decision-making processes.
13 Best Practices for Effective Entity Resolution
Entity Resolution is a complex task that demands careful consideration of data quality, matching algorithms, and overall data management strategies. Implementing best practices can significantly enhance the accuracy and efficiency of entity resolution processes. Here are some key recommendations:
Data Preprocessing
1. Standardization
Standardize data formats, units, and representations across different sources to reduce variations and improve matching accuracy.
2. Normalization
Normalize data values, especially for numerical attributes, to ensure consistency and comparability.
3. Tokenization
Break down text data into tokens (words or phrases) to facilitate matching based on commonalities.
Choosing the Right Matching Algorithm
4. Consideration of Data Characteristics
Select matching algorithms based on the nature of the data. For textual data, token-based or phonetic matching may be appropriate, while numerical data might benefit from similarity measures.
5. Performance Metrics
Evaluate the performance of matching algorithms using appropriate metrics such as precision, recall, and F1-score. Choose algorithms that balance accuracy and computational efficiency.
Iterative Refinement
6. Feedback Loops
Establish feedback loops that allow for continuous improvement. Regularly assess and refine the entity resolution process based on the feedback and evolving data.
7. Continuous Monitoring and Improvement
Implement monitoring mechanisms to track the performance of entity resolution over time. Periodically re-evaluate and update matching rules and algorithms as the dataset evolves.
Customization and Rule-based Approaches
8. Domain-specific Rules
Incorporate domain knowledge into the matching process by defining custom rules. This ensures that the approach aligns with the specific characteristics of the entities being matched.
9. Threshold Tuning
Adjust matching thresholds based on the specific requirements of the task. Fine-tune these thresholds to balance precision and recall according to the application needs.
Privacy and Security Considerations
10. Anonymization and Encryption
Implement anonymization techniques to protect sensitive information during the matching process. Encrypt data when necessary to ensure compliance with privacy regulations.
11. Access Controls
Implement access controls to restrict access to the entity resolution system, ensuring only authorized personnel can view or manipulate sensitive data.
Documentation and Communication
12. Document Matching Criteria
Document the criteria and rules used for matching. This documentation aids in transparency, reproducibility, and collaboration among team members.
13. Communication with Stakeholders
Communicate entity resolution results and potential challenges to stakeholders. Facilitate discussions to ensure alignment with business objectives and data quality expectations.
By following these best practices, you can improve the accuracy and reliability of the entity resolution processes, leading to better-informed decision-making and enhanced overall data quality.
How To Implement Entity Resolution In Python And R
Python and R offer several libraries and tools for performing entity resolution tasks. Here are some of the most popular options:
- entity-embed: This library focuses on transforming entities into vectors, enabling scalable record linkage using approximate nearest neighbours (ANNs). It’s particularly useful for large-scale ER tasks.
- pymatch: pymatch provides a set of functions for pairwise entity matching using various similarity measures and preprocessing techniques. It offers a flexible and customizable approach to ER.
- Record Linkage Toolkit (RLT): RLT is an R package that implements various ER algorithms, including probabilistic matching, record linkage with weights, and string similarity measures. It’s widely used in the data science community.
- Fuzzywuzzy: Fuzzywuzzy is a Python library that provides a suite of tools for fuzzy matching and string similarity calculation. It’s particularly useful for handling noisy and misspelt data.
- dedupe: dedupe is a Python library for duplicate detection, a closely related task to entity resolution. It offers a simple and efficient approach to identifying duplicate records based on various similarity measures.
The library choice will depend on the specific requirements of the ER task. Factors to consider include the datasets’ size and complexity, the desired accuracy level, and the availability of labelled data for training machine learning models.
Here’s a general workflow:
- Data Preparation: Import and clean the data, handling missing values, inconsistencies, and data types.
- Blocking: Divide the data into smaller, manageable blocks based on shared attributes or similarity measures.
- Candidate Pair Generation: Generate pairs of records from within each block that are potential matches.
- Similarity Calculation: Calculate the similarity between each pair of records using various measures, such as Levenshtein distance or Jaro-Winkler distance.
- Record Matching: Determine the true matches among the candidate pairs using a filtering or scoring approach.
- Clustering: Combine similar records into clusters, representing distinct entities in the data.
- Evaluation: Assess the performance of the ER algorithm using metrics like precision, recall, and F1 score.
Future Trends in Entity Resolution
Entity Resolution continues to evolve with advancements in technology, data science, and a growing emphasis on data quality.

As organizations strive for more accurate and efficient ways to manage and analyze data, several future trends in entity resolution are emerging:
- Integration with Big Data Technologies
- Scalability with Distributed Computing: Integration with big data frameworks like Apache Hadoop and Apache Spark allows entity resolution processes to scale horizontally, handling large datasets efficiently.
- Real-time Entity Resolution: Increasing demand for real-time analytics drives the development of entity resolution solutions that can provide immediate results, facilitating quicker decision-making.
- Advancements in Machine Learning Models
- Deep Learning for Entity Resolution: Leveraging deep learning architectures like neural networks for entity resolution tasks. These models can automatically learn complex patterns in data, potentially improving accuracy in matching.
- Semi-Supervised Learning: Utilizing semi-supervised learning approaches where models are trained on a combination of labelled and unlabeled data, allowing for more flexible and adaptive matching.
- Evolution of Privacy-Preserving Techniques
- Differential Privacy: Incorporating differential privacy techniques to protect sensitive information during the entity resolution process. This ensures compliance with stringent data privacy regulations.
- Federated Learning: Implementing federated learning approaches where models are trained on decentralized data sources without sharing raw data. This enhances privacy while still improving the accuracy of entity resolution.
- Integration with Knowledge Graphs
- Graph-based Entity Resolution: Incorporating knowledge graphs into entity resolution processes to leverage relationships and dependencies between entities. Graph databases can enhance matching accuracy by considering interconnected data.
- Ontology-based Matching: Using ontologies and semantic reasoning to improve the understanding of entity relationships, making entity resolution more context-aware and accurate.
- Explainability and Interpretability
- Interpretable Matching Models: The need for transparency in decision-making processes is leading to the development of entity resolution models that are more interpretable, making it easier to understand and trust the results.
- Explainable AI Techniques: Implementing explainable AI techniques to provide clear explanations for the decisions made during the entity resolution process. This is particularly crucial in industries where regulatory compliance is essential.
- Continuous Learning and Adaptive Strategies
- Adaptive Matching Strategies: Developing entity resolution systems that can adapt to changes in data distribution over time, ensuring continuous accuracy even as the dataset evolves.
- Active Learning: Incorporating active learning techniques where the model interacts with users to seek additional information, improving its performance over time.

As technology progresses, the future will likely see a combination of these trends, offering more robust, scalable, and privacy-aware solutions for managing and linking diverse datasets. Organizations that embrace these advancements will be better positioned to derive valuable insights from their data while maintaining high standards of accuracy and compliance.
Conclusion
Entity resolution is a critical process in data management and analytics that ensures data accuracy and consistency. As organizations grapple with increasingly diverse and voluminous datasets, the importance of robust entity resolution methodologies becomes ever more pronounced.
This exploration delved into the foundational aspects, understanding its definition, key components, and various challenges, such as data quality, scalability, and privacy concerns. We’ve also examined various techniques, ranging from deterministic and probabilistic matching to rule-based and machine learning-based approaches.
Looking ahead, the future holds exciting trends. The integration with big data technologies, advancements in machine learning models, and the evolution of privacy-preserving techniques signify a maturation of this field. Integration with knowledge graphs and the emphasis on explainability and interpretability further underscore the dynamic nature of entity resolution in response to evolving data landscapes.
In essence, entity resolution is a pivotal aspect of data governance and analytics, and its continual refinement and adaptation to emerging trends will play a crucial role in empowering organizations to derive meaningful insights and make informed decisions from their ever-expanding datasets.












0 Comments