What is Hierarchical Clustering?
Hierarchical clustering is a popular method in data analysis and data mining for grouping similar data points or objects into clusters or groups. It creates a hierarchical representation of data by successively merging or splitting clusters. There are two main types of hierarchical clustering: agglomerative and divisive.
Table of Contents
Agglomerative Hierarchical Clustering
Agglomerative clustering starts with each data point as its own cluster and then iteratively merges the closest clusters into larger clusters until only one cluster remains. The steps involved in agglomerative clustering are as follows:
- Begin with each data point as a separate cluster.
- Find the two closest clusters and merge them into a single cluster.
- Repeat step 2 until all data points are in one cluster, forming a hierarchy of clusters.
The result of agglomerative clustering is often visualized as a dendrogram, a tree-like diagram showing the hierarchical relationships between clusters. You can cut the dendrogram at a certain level to obtain a specific number of clusters.
Divisive Hierarchical Clustering
- Divisive hierarchical clustering takes the opposite approach. It starts with all data points in a single cluster and then recursively splits clusters into smaller clusters until each data point is in its own cluster. However, divisive clustering is less common than agglomerative clustering.
The choice of distance metric (how to measure the similarity between data points) and linkage criterion (how to determine the distance between clusters) plays a crucial role in the effectiveness of hierarchical clustering. Typical distance metrics include Euclidean distance, Manhattan distance, and cosine similarity, while popular linkage criteria include single linkage, complete linkage, and average linkage.
Hierarchical clustering has several advantages, such as the ability to visualize the hierarchy of clusters, not needing the number of clusters to be specified beforehand, and providing a comprehensive view of data structure. However, it can be computationally expensive for large datasets and may not be suitable for high-dimensional data.
How Does Hierarchical Clustering Work?
Hierarchical clustering is a technique that hierarchizes data points or objects into clusters. It starts with each data point as its cluster and then iteratively merges or splits clusters until a specific criterion is met. Here’s a step-by-step explanation of how hierarchical clustering works:
1. Initialization:
- Begin with each data point as a separate cluster. In other words, if you have ‘n’ data points, you start with ‘n’ clusters, each containing one data point.
2. Distance Calculation:
- Calculate the pairwise distances or similarities between all clusters. This step requires a distance metric or similarity measure, such as Euclidean distance, Manhattan distance, or cosine similarity, depending on the nature of your data and problem.
3. Merging Clusters (Agglomerative Clustering):
- Find the two closest clusters based on the distance/similarity metric. These clusters are merged into a single cluster.
- The choice of which clusters to merge can be determined by different linkage criteria, such as:
- Single Linkage: Merge clusters based on the closest pair of data points between the clusters.
- Complete Linkage: Merge clusters based on the farthest pair of data points between the clusters.
- Average Linkage: Merge clusters based on the average distance between all pairs of data points between the clusters.
- Centroid Linkage: Merge clusters based on the distance between the clusters’ centroids (mean points).
4. Update the Distance Matrix:
- Recalculate the distances or similarities between the newly formed and the remaining clusters.
- This step reduces the number of clusters by one.
5. Repeat Steps 3 and 4:
- Continue merging the closest clusters and updating the distance matrix until only one cluster remains. This process forms a hierarchy of clusters.
6. Creating a Dendrogram:
- As clusters are merged, you can represent the hierarchical structure using a dendrogram. A dendrogram is a tree-like diagram visually showing clusters’ merging processes and relationships.
7. Cutting the Dendrogram:
- You can cut the dendrogram at a certain level to obtain a specific number of clusters. The height at which you cut the dendrogram determines the number of clusters you get. Choosing the right level often involves domain knowledge or methods like the elbow method or silhouette analysis.
8. Cluster Assignment:
- Once you’ve determined the desired number of clusters, you can assign each data point to its corresponding cluster based on the hierarchical structure you’ve created.
Hierarchical clustering is a versatile method because it doesn’t require you to specify the number of clusters in advance. It allows you to explore different levels of granularity in your data, from a few large clusters to many small clusters. Additionally, the dendrogram visually represents how data points are related, making it easier to interpret the results. However, hierarchical clustering can be computationally expensive for large datasets.
Practical Applications of Hierarchical Clustering
Hierarchical clustering, with its ability to uncover intricate structures within data, finds applications in various fields. Here are some practical applications of hierarchical clustering that demonstrate its versatility and usefulness:
1. Biology and Genetics:
- Gene Expression Analysis: Hierarchical clustering is widely employed in genomics to analyze gene expression data. By clustering genes and samples based on their expression profiles, researchers can identify patterns related to diseases, biological processes, or responses to treatments.
- Phylogenetics: Biologists use hierarchical clustering to construct phylogenetic trees depicting the evolutionary relationships between species. It helps classify organisms based on genetic similarities, enabling us to trace evolutionary history.
- Proteomics: In the study of proteins, hierarchical clustering assists in grouping proteins with similar functions or structures. This aids in understanding complex protein interactions and their roles in biological processes.
2. Marketing and Customer Segmentation:
- Customer Segmentation: Businesses use hierarchical clustering to segment their customer base. Companies can tailor marketing strategies, product recommendations, and pricing to specific customer groups by clustering customers with similar purchasing behaviour or demographics.
- Market Basket Analysis: Retailers apply hierarchical clustering to identify patterns in customer purchasing habits. This helps optimize store layouts, product placements, and promotions to increase sales and customer satisfaction.
3. Social Sciences:
- Demographic Analysis: Social scientists employ hierarchical clustering to group regions or populations based on demographic data. This can aid in understanding regional disparities, migration patterns, and the impact of social policies.
- Psychology and Sociology: Researchers use hierarchical clustering to classify individuals or households based on psychological or sociological attributes. It helps identify common traits and behaviours within specific groups.
4. Image and Document Analysis:
- Image Segmentation: In image processing, hierarchical clustering assists in segmenting images into regions with similar characteristics, such as texture, colour, or intensity. This is crucial in computer vision applications like object recognition and medical image analysis.
- Text Clustering: In natural language processing (NLP), hierarchical clustering is used to group documents or text data with similar content. This aids in information retrieval, topic modelling, and content recommendation systems.
5. Environmental Science:
- Ecological Classification: Environmental scientists use hierarchical clustering to classify ecosystems or ecological communities based on environmental parameters. This supports conservation efforts, biodiversity studies, and ecosystem management.
6. Finance and Risk Management:
- Portfolio Optimization: Hierarchical clustering is employed in finance to group financial assets with similar risk-return profiles. This helps investors construct diversified portfolios and manage risk effectively.
- Credit Risk Assessment: Banks and financial institutions use hierarchical clustering to assess the credit risk of borrowers by grouping them based on credit history and financial characteristics.
7. Healthcare and Medicine:
- Patient Stratification: In healthcare, hierarchical clustering is used to stratify patients based on medical data. This can lead to more personalized treatment plans and improved healthcare outcomes.
- Drug Discovery: Pharmaceutical companies utilize hierarchical clustering to group compounds with similar chemical properties. It aids in drug discovery by identifying potential candidates for further testing.
In these applications, hierarchical clustering offers insights, simplifies complex data, and assists decision-making processes. Its ability to reveal hierarchical structures within data makes it a valuable tool across various domains.
What is hierarchical clustering used for in machine learning?
Hierarchical clustering is a widespread technique in machine learning and data analysis for grouping data points or objects into clusters based on their similarity or dissimilarity. It’s commonly used in machine learning for various purposes, including exploratory data analysis, feature engineering, and data preprocessing. Here are some ways hierarchical clustering is applied in machine learning:
- Exploratory Data Analysis (EDA): Hierarchical clustering is often used during the initial stages of data analysis to gain insights into the data structure. It helps identify natural groupings or patterns within the data, which can guide further analysis and model selection.
- Feature Engineering: Hierarchical clustering can be used to engineer new features for machine learning models. For example, you can create categorical features representing cluster assignments for each data point, which can be used as input for classification or regression models.
- Anomaly Detection: By using hierarchical clustering, you can identify data points that do not belong to well-defined clusters. Outliers or anomalies can be detected as data points far from any cluster’s centroid.
- Data Preprocessing: Hierarchical clustering can be used to preprocess data before applying other machine learning algorithms. For example, natural language processing is used for text document clustering before topic modelling or text classification.
- Image Segmentation: In computer vision and image processing, hierarchical clustering is used for image segmentation. It can group pixels with similar colour, texture, or intensity values to identify distinct objects or regions within an image.
- Customer Segmentation: Businesses use hierarchical clustering to segment their customer base for targeted marketing. Companies can tailor their marketing strategies and product recommendations by clustering customers with similar purchasing behaviour.
- Recommendation Systems: Hierarchical clustering can create user or item clusters in recommendation systems. This allows for personalized recommendations based on similar user profiles or item attributes.
- Social Network Analysis: In social network analysis, hierarchical clustering can group individuals based on their network connections or behaviours. It helps uncover community structures within networks.
- Text Mining: Text documents can be clustered hierarchically based on their content, which helps organize extensive document collections, summarize topics, or build content recommendation systems.
Advantages and Limitations
Hierarchical clustering is a powerful and flexible method for data analysis. Still, it has advantages and limitations that should be considered when choosing it as a clustering technique.
Advantages
1. Hierarchy of Clusters:
- Interpretability: Hierarchical clustering visually represents the data’s structure as a dendrogram. This hierarchy allows users to explore and interpret the relationships between clusters at different levels of granularity.
2. No Need for Predefined Clusters:
- Flexibility: Unlike other clustering methods requiring you to specify the number of clusters in advance, hierarchical clustering does not. It can reveal the natural grouping of data points without prior assumptions about the number of clusters.
3. Handling Various Cluster Shapes:
- Robustness: Hierarchical clustering can handle clusters of different shapes and sizes, including irregularly shaped clusters or clusters with varying densities.
4. Agglomerative and Divisive Approaches:
- Versatility: Hierarchical clustering offers agglomerative and divisive approaches, allowing users to choose the best method for their data and objectives.
5. Outlier Detection:
- Anomaly Identification: It can be used for outlier detection by isolating data points that do not fit well into any cluster.
Limitations
1. Computational Complexity:
- Scalability: Hierarchical clustering can be computationally expensive, especially for large datasets, because it requires the calculation of distances between all data points and clusters at each step.
2. Sensitivity to Noise:
- Noise Sensitivity: Hierarchical clustering is sensitive to noise and outliers, which can lead to suboptimal cluster assignments if not correctly addressed.
3. Lack of Reversibility:
- Irreversibility: Once clusters are merged in agglomerative hierarchical clustering, they cannot be split apart in the same analysis. Divisive hierarchical clustering, on the other hand, allows splitting clusters but is less commonly used.
4. Subjectivity in Dendrogram Cutting:
- Dendrogram Cutting: Determining the optimal number of clusters by cutting the dendrogram can be subjective and may depend on domain knowledge or arbitrary thresholds. It can result in different clusterings based on how the dendrogram is cut.
5. Memory Usage:
- Large Memory Footprint: When working with large datasets, hierarchical clustering can consume significant memory due to the storage of distance matrices and dendrograms.
6. Lack of Global Optimality:
- Lack of Global Optimum: The hierarchical merging process is a greedy algorithm that may not always lead to the globally optimal clustering solution. It depends on the choice of distance metric, linkage criteria, and starting conditions.
How To Implement Hierarchical Clustering
Implementing hierarchical clustering involves several key steps, from choosing the proper distance metric and linkage criterion to visualizing and interpreting the results. This section will guide you through the practical aspects of implementing hierarchical clustering.
1. Choosing the Right Distance Metric:
One of the critical decisions when implementing hierarchical clustering is selecting an appropriate distance metric. The choice of distance metric depends on the nature of your data and the problem you are solving. Typical distance metrics include:
- Euclidean Distance: Suitable for continuous numeric data when the scale of the variables is meaningful.
- Manhattan Distance: Works well with numeric data and is less sensitive to outliers than Euclidean distance.
- Cosine Similarity: Appropriate for text and high-dimensional data, measuring the cosine of the angle between vectors.
- Jaccard Distance: Used for binary data (e.g., presence/absence), measuring the dissimilarity between sets.
- Correlation Distance: Applicable to data where the relationship between variables is more important than their absolute values.
Choosing the proper distance metric is crucial, significantly influencing the clustering results.
2. Selecting a Linkage Criterion:
Another critical decision is selecting a linkage criterion, which determines how the distance between clusters is computed. The linkage criterion choice affects the resulting clusters’ shape and structure. Standard linkage criteria include:
- Single Linkage: Measures the distance between the closest data points of two clusters. It tends to create long, narrow clusters and is sensitive to outliers.
- Complete Linkage: Measures the distance between the farthest data points of two clusters. It tends to produce compact, spherical clusters and is less sensitive to outliers.
- Average Linkage: Calculates the average distance between all pairs of data points from two clusters. It balances the effects of single and complete linkage.
- Ward’s Method: Minimizes the variance of the distances within clusters when merging. It often results in equally sized, balanced clusters.
The linkage criterion choice should align with your analysis’s specific goals.
3. Hierarchical Clustering Algorithms:
There are various algorithms to implement hierarchical clustering, such as agglomerative clustering and divisive clustering. Agglomerative clustering is more commonly used and is available in most libraries and software packages. You can use libraries like Scikit-Learn in Python or functions like hclust in R to perform hierarchical clustering.
4. Dendrogram Visualization:
Once you’ve performed hierarchical clustering, you’ll typically obtain a dendrogram, a tree-like diagram showing the hierarchy of clusters. Visualizing the dendrogram helps you understand the relationships between clusters and decide how many to select.
5. Determining the Number of Clusters:
You can cut the dendrogram at a certain height or level to determine the number of clusters. This step can be subjective, and different cut levels may yield different clusterings. Standard methods for deciding the number of clusters include:
- Elbow Method: Look for an “elbow” point in the dendrogram where the rate of change in cluster dissimilarity slows.
- Silhouette Analysis: Measure the quality of clustering at different cut levels by examining the silhouette score, which quantifies how similar each data point is to its cluster compared to others.
6. Cluster Assignment:
Once you’ve determined the number of clusters, you can assign data points to their respective clusters based on the hierarchical structure you’ve obtained.
7. Post-processing and Interpretation:
After clustering, it’s essential to interpret the results. Analyze the characteristics of each cluster and understand the patterns or relationships the clustering has uncovered. This step often involves domain expertise and can lead to actionable insights or further analysis.
Implementing hierarchical clustering requires thoughtful choices regarding distance metrics and linkage criteria and careful interpretation of the resulting clusters. It’s a versatile method suitable for various data types and problem domains, making it a valuable tool in your data analysis toolkit.
Visualizing and Interpreting Hierarchical Clustering
Visualizing and interpreting hierarchical clustering results is essential for gaining insights from your data and making informed decisions. This section will explore how to visualize and analyze hierarchical clustering outcomes effectively.
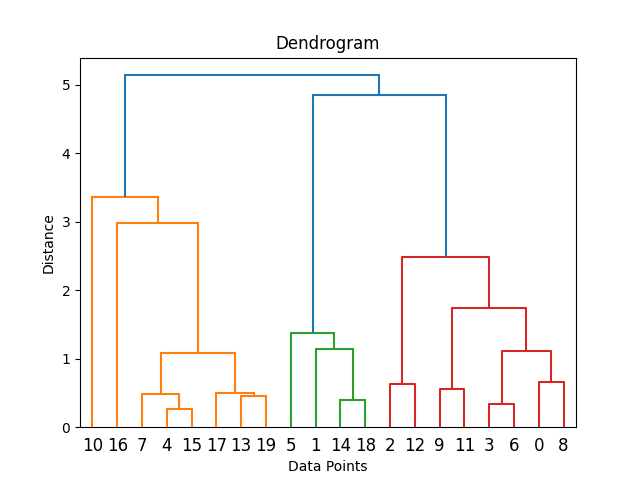
1. Dendrogram Visualization:
A dendrogram is a tree-like diagram that illustrates the hierarchy of clusters formed during hierarchical clustering. It is a powerful tool for visualizing the relationships between data points and clusters. Here’s how to interpret a dendrogram:
- Height on the Y-Axis: The vertical lines in a dendrogram represent individual data points (leaves) and clusters (nodes). The height at which two branches merge represents the distance those clusters were combined.
- Branches and Subtrees: The branches in a dendrogram show the merging of clusters. Each branching point indicates a fusion of clusters, with the height of the branch indicating the dissimilarity at which the merge occurred. Subtrees represent groups of similar data points or clusters.
- Cutting the Dendrogram: To determine the number of clusters, you can cut the dendrogram at a specific height or level. The resulting subtrees represent the individual clusters. The choice of where to cut depends on your objectives and the desired number of clusters.
2. Interpreting Cluster Characteristics:
Once you have identified clusters using the dendrogram, it’s crucial to interpret the characteristics of each cluster. Here are some steps to follow:
- Cluster Profiles: Examine the data points within each cluster to understand their standard features, patterns, or behaviours. This can involve calculating summary statistics, visualizing data distributions, or using domain knowledge to describe each cluster’s characteristics.
- Naming Clusters: Assign meaningful names or labels to clusters based on the insights gained. For example, in customer segmentation, clusters can be labelled as “High-Value Customers” or “Occasional Shoppers” to make the interpretation more intuitive.
- Cluster Validation: Assess the quality of your clustering results using internal validation metrics (e.g., silhouette score) or external validation measures if ground truth labels are available. This helps ensure that the clustering solution aligns with the underlying data structure.
3. Heatmaps and Data Visualizations:
In addition to dendrograms, you can use heatmaps and other data visualizations to gain deeper insights into cluster characteristics:
- Heatmaps: Create a heatmap that displays the distance or dissimilarity matrix of the data, with rows and columns reordered based on hierarchical clustering. Heatmaps provide a visual representation of data patterns within and between clusters.
- Principal Component Analysis (PCA): Apply PCA to reduce the dimensionality of your data and visualize it in a lower-dimensional space. PCA can help uncover the key features driving cluster formation.
4. Exploring Cluster Relationships:
Hierarchical clustering allows you to explore relationships not only within clusters but also between clusters:
- Cluster Similarity: Evaluate the similarity or dissimilarity between clusters by comparing their centroids, medoids, or other representative points. This can help identify higher-level patterns or groupings.
- Hierarchy Levels: Examine the hierarchy of clusters at different dendrogram levels to identify fine-grained and coarse-grained structures in your data. This can be especially valuable when dealing with complex datasets.
5. Iterative Analysis and Refinement:
Hierarchical clustering is an iterative process. Don’t hesitate to revisit and refine your analysis. You can experiment with different linkage criteria, distance metrics, or dendrogram cut heights to see how they affect the clustering results.
6. Communication of Results:
Effectively communicate your findings to stakeholders or colleagues. Visualizations, cluster descriptions, and insights should be presented clearly and understandably, making it easy for others to grasp the implications of the clustering.
Visualizing and interpreting results involves examining dendrograms, exploring cluster characteristics, using data visualizations, and understanding cluster relationships. This process helps you uncover patterns, make informed decisions, and communicate valuable insights from your data analysis.
Example of how to implement hierarchical clustering in Python
Hierarchical clustering in Python can be implemented using various libraries, with SciPy being one of the most commonly used libraries for this purpose. Here’s a step-by-step guide on how to perform it using Python:
1. Import Required Libraries: You’ll need SciPy and other relevant libraries for data manipulation and visualization. Make sure you have them installed. You can install them using pip if you haven’t already:
pip install scipy Here’s how you import the necessary libraries:
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt 2. Prepare Your Data: Prepare your data as a NumPy array or pandas DataFrame, with each row representing a data point and each column representing a feature.
# Generate synthetic data for example purposes
np.random.seed(0)
data = np.random.randn(20, 2)3. Calculate the Distance Matrix: The pairwise distances between your data points. You can use various distance metrics, such as Euclidean distance or others available in SciPy’s pdist function:
from scipy.spatial import distance
distance_matrix = distance.pdist(data, metric='euclidean') 4. Perform Hierarchical Clustering: Use the linkage function in SciPy to perform clustering on the distance matrix. You’ll also specify the linkage criterion (e.g., ‘ward’, ‘single’, ‘complete’, ‘average’):
linkage_matrix = sch.linkage(distance_matrix, method='ward') 5. Create a Dendrogram: A dendrogram is a tree-like diagram that visualizes the hierarchical clustering results. You can use Matplotlib to create and display the dendrogram:
dendrogram = sch.dendrogram(linkage_matrix)
plt.xlabel('Data Points')
plt.ylabel('Distance')
plt.title('Dendrogram')
plt.show() 6. Cutting the Dendrogram: To determine the number of clusters, you can cut the dendrogram at a specific height or level. This step is subjective and depends on your problem and objectives. You can do this manually or programmatically:
from scipy.cluster.hierarchy import fcluster
# Set the threshold for cutting the dendrogram
threshold = 2
# Assign each data point to a cluster based on the threshold
clusters = fcluster(linkage_matrix, threshold, criterion='distance') 7. Cluster Assignment: Once you’ve determined the number of clusters, you can assign data points to their corresponding clusters using the clusters variable.
8. Visualize the Clusters: Visualize the clusters by plotting them and colouring data points according to their assigned cluster labels:
plt.scatter(data[:, 0], data[:, 1], c=clusters, cmap='viridis')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Hierarchical Clustering Results')
plt.show() 
This example demonstrates the basic steps for hierarchical clustering in Python using SciPy. Remember that hierarchical clustering is a versatile technique, and you can adapt these steps to your specific data and problem domain. You may also want to explore different distance metrics and linkage criteria to fine-tune your clustering results.
Conclusion
This comprehensive guide explored the fascinating world of hierarchical clustering, a versatile and robust data analysis and machine learning technique. Hierarchical clustering offers a data-driven approach to uncovering patterns, relationships, and structures within your data. Let’s recap some key takeaways:
- Hierarchical Structure: Hierarchical clustering constructs a hierarchy of clusters, allowing you to explore the data at different levels of granularity. This hierarchical representation provides valuable insights into the natural grouping of data points.
- Steps in Hierarchical Clustering: The process involves initializing clusters, calculating distances, merging or splitting clusters, and visualizing the results using dendrograms. The choice of distance metric and linkage criterion impacts the clustering outcome.
- Practical Applications: It finds applications in diverse domains, including biology, marketing, social sciences, image processing, and more. It aids in customer segmentation, anomaly detection, and exploratory data analysis.
- Advantages: It offers interpretability, flexibility in the number of clusters, and the ability to handle various cluster shapes and sizes. It provides a visual representation of data structure through dendrograms.
- Limitations: Considerations include computational complexity for large datasets, sensitivity to noise and outliers, and the subjective nature of dendrogram cutting. Careful choice of parameters is essential.
- Implementation: You can implement it in Python using libraries like SciPy. The steps involve data preparation, distance matrix calculation, clustering, dendrogram creation, determining the number of clusters, cluster assignment, and visualization.
- Interpretation: Interpreting the results involves analyzing dendrograms, understanding cluster characteristics, exploring relationships between clusters, and using various data visualizations.
- Iterative Process: Hierarchical clustering often requires experimentation with different settings, such as distance metrics and linkage criteria, to achieve meaningful clustering results.
In your data analysis journey, hierarchical clustering is a valuable tool to uncover hidden insights, support decision-making, and communicate complex structures within your data. It empowers you to explore data relationships in a way that other clustering techniques may not offer. Whether segmenting customers, classifying genes, or organizing text documents, hierarchical clustering can provide valuable solutions and guide your data-driven endeavours.












0 Comments