What is a Universal Sentence Encoder?
The Universal Sentence Encoder (USE) is a powerful tool in natural language processing (NLP) developed by Google. Its primary function is to transform textual data into high-dimensional vectors, also known as embeddings, that capture the semantic meaning of sentences. Unlike traditional word embeddings representing individual words, the USE generates embeddings for entire sentences or short paragraphs.
Table of Contents
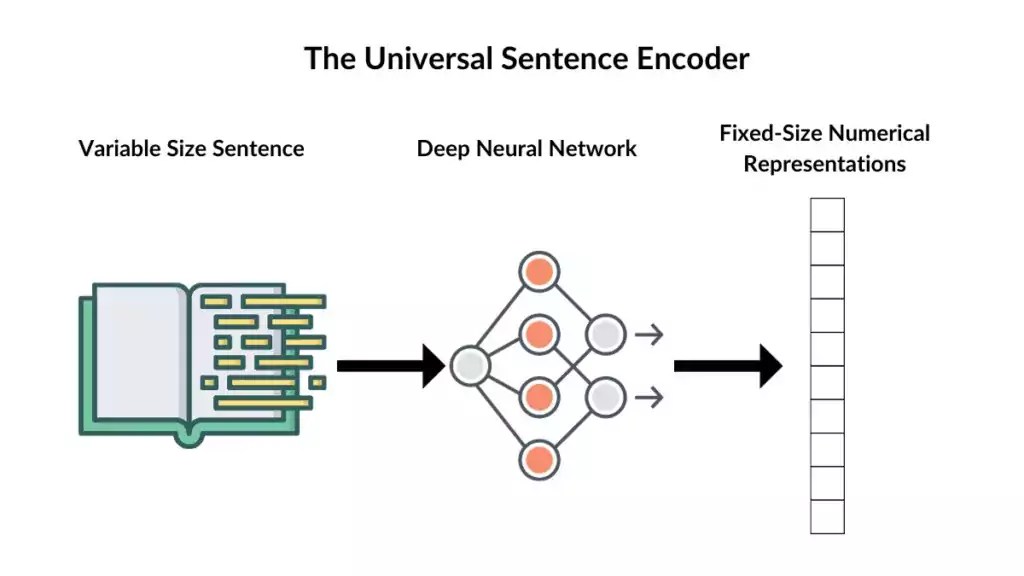
At its core, the Universal Sentence Encoder employs a deep neural network that has been pre-trained on a large corpus of text from diverse sources, allowing it to understand and encode the meaning of sentences in a way that captures semantic similarities and relationships between them. It’s built to generate fixed-size numerical representations for variable-length sentences, facilitating efficient computation and analysis.
Its ability to handle various languages, writing styles, and sentence structures makes the USE remarkably versatile and mighty. It can effectively process and understand text in multiple languages without requiring language-specific models.
The encoder’s output vectors encode semantic meaning to facilitate tasks like semantic similarity comparison, sentiment analysis, text classification, information retrieval, and more. Furthermore, the USE’s embeddings are often used as a starting point for transfer learning in downstream NLP tasks. This allows developers to leverage the pre-trained model’s knowledge and fine-tune it for specific applications, reducing the need for extensive labelled data and training time.
In essence, the Universal Sentence Encoder bridges human language and machine understanding, enabling AI systems to comprehend and interpret text in a manner that resembles human-like comprehension. Its adaptability, accuracy, and broad applicability have made it valuable in various industries, including customer service, search engines, chatbots, sentiment analysis, and beyond.
Understanding the Universal Sentence Encoder
The Universal Sentence Encoder is a transformative force in natural language understanding, wielding a sophisticated mechanism that transcends traditional word embeddings to encapsulate the essence of entire sentences. Here’s a deeper dive into how this remarkable tool functions:
Neural Architecture
- Deep Learning Foundation: Built upon a deep neural network architecture, the USE utilizes Transformer models or other advanced architectures for its encoding mechanism.
- Encoder Layers: Multiple layers capture complex linguistic patterns and semantic meanings, enabling the extraction of rich contextual information from sentences.
- Training Data: Trained on diverse and extensive corpora, the model has learned to generate embeddings that encapsulate the semantic essence of sentences.
The Encoding Process
- Semantic Representation: Unlike word embeddings that focus on individual words, USE focuses on entire sentences, capturing semantic meanings and contextual information.
- Fixed-Length Vectors: Generates fixed-length numerical representations for variable-length sentences, enabling efficient computations and comparisons.
- Language Agnostic: Capable of encoding sentences across multiple languages, showcasing adaptability and universality.

USE focuses on entire sentences, capturing semantic meanings and contextual information.
How Does a Universal Sentence Encoder Compare to Traditional Embeddings?
The Universal Sentence Encoder (USE) represents a paradigm shift in natural language processing, diverging significantly from conventional word embeddings. Explore the fundamental disparities between USE’s sentence-level embeddings and traditional word embeddings:
1. Scope of Representation
- Word Embeddings: Focus solely on individual words, mapping them to high-dimensional vectors based on co-occurrence or contextual information.
- Sentence Embeddings (USE): Captures the semantic essence of entire sentences, considering the holistic meaning and context.
2. Semantic Similarity vs. Lexical Relationships
- Word Embeddings: Emphasize lexical relationships—associations between individual words and their meanings.
- USE Embeddings: Prioritize semantic similarity, focusing on understanding sentences’ deeper contextual and semantic relevance.
3. Contextual Understanding
- Word Embeddings: Lack contextual awareness, providing fixed representations for words irrespective of sentence context.
- USE Embeddings: Contextually aware, encoding sentences while considering the surrounding words, their order, and the overall sentence structure.
4. Granularity of Representation
- Word Embeddings: Offer fine-grained representations for individual words, lacking the ability to capture entire sentence semantics.
- USE Embeddings: Provide coarse-grained representations that encapsulate the comprehensive meaning of sentences.
5. Applications and Use Cases
- Word Embeddings: Commonly employed in tasks like word similarity, language modelling, and named entity recognition.
- USE Embeddings: Applied in tasks requiring semantic understanding, such as sentiment analysis, semantic search, and transfer learning in NLP.
6. Flexibility and Universality
- Word Embeddings: Language-specific, requiring separate models for different languages.
- USE Embeddings: Language-agnostic, capable of encoding sentences across multiple languages, showcasing universality in understanding semantics.
The distinction between the Universal Sentence Encoder and traditional word embeddings lies in their scope, granularity, and approach towards semantic understanding. While word embeddings focus on lexical relationships, the USE’s emphasis on holistic sentence semantics marks a significant leap forward in natural language comprehension.
Technical Overview
The Universal Sentence Encoder (USE) operates on a foundation of advanced technical concepts, employing intricate methodologies to distil the semantic essence of sentences into high-dimensional vectors. Let’s delve into the technical underpinnings that empower this transformative tool:
1. Embedding Dimensionality
- High-Dimensional Space: Generates embeddings in high-dimensional numerical vectors (typically 512 dimensions or higher).
- Semantic Representation: Encodes rich semantic information, capturing diverse linguistic nuances within a fixed-length representation.
2. Pre-trained Models and Transfer Learning
- Pre-trained Models: Utilizes pre-trained neural networks on extensive corpora to develop a fundamental understanding of semantic relationships.
- Transfer Learning: Serves as a springboard for transfer learning, allowing fine-tuning on specific tasks or domains using the pre-trained embeddings.
3. Training Methodologies
- Unsupervised Learning: Learns representations from vast amounts of unlabeled text data, leveraging the power of unsupervised learning.
- Semantic Generalization: Generalizes semantic knowledge from diverse textual contexts, facilitating a broader understanding of sentence semantics.
4. Neural Network Architecture
- Transformer Models: Often employs Transformer-based architectures due to their effectiveness in capturing long-range dependencies and contextual information.
- Encoder Layers: Comprises multiple encoder layers, each responsible for encoding distinct levels of semantic information.
5. Semantic Similarity Measurement
- Cosine Similarity: Utilizes cosine similarity metrics to measure the similarity between encoded sentence vectors.
- Semantic Relationships: Quantifies semantic relationships between sentences, aiding tasks like semantic search, paraphrase identification, and clustering.
6. Computational Efficiency
- Fixed-Length Representations: Generates fixed-length vectors for variable-length sentences, ensuring computational efficiency in processing.
- Parallel Processing: Optimizes computations through parallel processing, enhancing the speed and scalability of semantic encoding.
7. Model Accessibility and Implementation
- TensorFlow and TensorFlow Hub: Offers accessible implementations through TensorFlow and TensorFlow Hub, enabling developers to incorporate USE into their projects efficiently.
The technical fabric of the Universal Sentence Encoder intricately weaves together concepts from deep learning, unsupervised learning, and transfer learning, resulting in a tool adept at distilling intricate semantics from textual data. Its proficiency in semantic representation and applicability across diverse domains solidify its standing as a cornerstone in natural language understanding and processing.
Application in Understanding Semantics
The Universal Sentence Encoder (USE) is a technical achievement and a catalyst for advancements across various domains reliant on natural language understanding. Its applications extend far and wide, showcasing its prowess in deciphering the intricate semantics of sentences:
1. Semantic Information Extraction
- Contextual Understanding: Deciphers nuanced contextual cues within sentences, discerning intent, tone, and implications.
- Capturing Intent: Identifies underlying intentions or meanings embedded in the text, facilitating accurate interpretation.
2. Semantic Similarity Assessment
- Semantic Comparison: Measures semantic similarity between sentences, allowing for precise identification of related or similar content.
- Paraphrase Detection: Recognizes paraphrased or semantically equivalent sentences, aiding in plagiarism detection or content recommendation systems.
3. Semantic Search and Information Retrieval
- Enhanced Search Relevance: Empowers search engines with the ability to retrieve results based on semantic relevance rather than keyword matching alone.
- Improved Information Retrieval: Facilitates more accurate information retrieval by understanding the semantics of user queries and content.
4. Sentiment Analysis and Opinion Mining
- Sentiment Understanding: Analyzes sentiment by comprehending the nuanced expressions and contextual clues within sentences.
- Opinion Extraction: Extracts opinions or subjective expressions, aiding in understanding public opinion or customer feedback.
5. Transfer Learning and Downstream NLP Tasks
- Foundation for Transfer Learning: Serves as a foundational model for transfer learning, facilitating adaptation to specific NLP tasks.
- Fine-tuning Capabilities: Enables fine-tuning on domain-specific data, enhancing performance in sentiment analysis, classification, or question answering.
6. Conversational AI and Chatbots
- Conversational Understanding: Enhances chatbot capabilities by comprehending user queries contextually and responding more intelligently.
- Context Retention: Maintains context across conversational turns, enabling more coherent and contextually relevant responses.
The Universal Sentence Encoder’s applications extend across diverse sectors, from improving search engine relevance to enhancing conversational AI. Its ability to grasp the semantic fabric of sentences transcends mere understanding, empowering systems to interpret language with a depth akin to human comprehension.
Understanding the Universal Sentence Encoder requires unravelling the intricacies of its neural architecture, encoding processes, and the fundamental departure it represents from traditional word embeddings. This comprehensive grasp sets the stage for exploring its vast applications in natural language understanding and various NLP applications.
Is the Universal Sentence Encoder Only Trained in English, or Can it Process Text in Other Languages?
The Universal Sentence Encoder (USE) is not limited to English text—it can process text in multiple languages. While the original training of the USE might have primarily involved English text data, its design allows it to generalize well to other languages. It leverages transfer learning, a technique that enables models trained on one task to be applied to another related task to understand and encode semantics across various languages.
The USE’s ability to handle multilingual text stems from its architecture, which captures semantic meaning and context at a sentence level. It learns to generate fixed-length vectors representing the essence of sentences, allowing it to encode semantic information regardless of the language.
This universality in processing various languages makes the USE a valuable tool in multilingual natural language processing tasks. When applied to text in languages beyond English, it retains its capability to encode the semantic content effectively, enabling tasks such as semantic similarity measurement, text classification, sentiment analysis, and more across multiple languages.
How to Use a Universal Sentence Encoder in TensorFlow for Text Classification
Text classification with the Universal Sentence Encoder involves using the encoded sentence embeddings as input to a classification model. Here’s a basic example of how you might approach text classification using TensorFlow and the Universal Sentence Encoder:
Implementation Steps:
1. Load Libraries
import tensorflow as tf
import tensorflow_hub as hub2. Load USE and Prepare Data
# Load the Universal Sentence Encoder module
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
use = hub.load(module_url)
# Sample training data (features and labels)
train_data = [
("Text sample 1", 1), # (text, label)
("Text sample 2", 0),
# Add more samples as needed
]
# Separate features and labels
train_sentences, train_labels = zip(*train_data)
# Encode training sentences
train_embeddings = use(train_sentences)3. Build and Train a Classification Model
# Build a simple classification model using TensorFlow
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(512,)), # Adjust input shape if needed
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid') # Binary classification example
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model with encoded sentence embeddings
model.fit(train_embeddings, train_labels, epochs=10, batch_size=32)4. Prepare Test Data and Evaluate
# Sample test data for evaluation
test_data = [
("Test sample 1", 1),
("Test sample 2", 0),
# Add more test samples as needed
]
# Separate test features and labels
test_sentences, test_labels = zip(*test_data)
# Encode test sentences
test_embeddings = use(test_sentences)
# Evaluate the model on the test data
loss, accuracy = model.evaluate(test_embeddings, test_labels)
print(f"Test accuracy: {accuracy}")This example demonstrates how you can use the Universal Sentence Encoder to encode text and apply these embeddings as inputs to a simple classification model using TensorFlow. Adjust the architecture and hyperparameters based on your text classification task and dataset characteristics.
Applications of a Universal Sentence Encoder in NLP
The Universal Sentence Encoder (USE) is a linchpin in various Natural Language Processing (NLP) applications, reshaping how machines understand and interpret textual data. Its versatility and semantic grasp have paved the way for transformative advancements across multiple domains:
1. Text Classification and Categorization
- Sentiment Analysis: Determines sentiments within the text by comprehending the semantic nuances and contextual clues.
- Topic Categorization: Classifies text into specific topics or categories based on semantic similarities, enhancing content organization.
2. Information Retrieval and Search Engines
- Semantic Search Enhancement: Enhances search engines by considering semantic relevance, improving search accuracy and result relevance.
- Question Answering Systems: Enables systems to comprehend user queries contextually, providing more accurate answers.
3. Semantic Similarity and Clustering
- Semantic Similarity Measurement: Measures the semantic proximity between sentences, aiding in content recommendation systems or clustering similar content.
- Paraphrase Identification: Identifies paraphrased or semantically equivalent sentences, assisting in tasks like summarization or text simplification.
4. Conversational AI and Chatbots
- Conversational Understanding: Enhances chatbot capabilities by comprehending the context and intent behind user queries, leading to more contextually relevant responses.
- Context Retention: Maintains conversational context across dialogue turns, ensuring conversation coherence and relevance.
5. Named Entity Recognition and Entity Linking
- Entity Identification: Facilitates the recognition of named entities within the text, understanding the semantic context around them.
- Entity Linking: Connects recognized entities to relevant knowledge bases, enhancing information retrieval and context enrichment.
6. Sentiment Analysis in Customer Service
- Customer Feedback Analysis: Analyzes customer feedback by comprehending sentiment and contextual nuances, aiding in improving products or services.
- Sentiment-driven Decision Making: Provides insights for businesses based on sentiment analysis, guiding strategic decision-making processes.
7. Transfer Learning in NLP Tasks
- Foundation for Transfer Learning: Serves as a foundational model for transfer learning, enabling fine-tuning on specific tasks like classification, summarization, or machine translation.
- Domain Adaptation: Adapting to domain-specific data enhances performance in specialized NLP tasks.
The Universal Sentence Encoder’s applications span a broad spectrum, empowering NLP systems to interpret language with a depth and sophistication that mirrors human comprehension. Its transformative impact extends to diverse industries, revolutionizing how textual data is processed, analyzed, and utilized.
Limitations and Future Developments
While the Universal Sentence Encoder (USE) is a pinnacle in natural language processing, it also has certain limitations. Additionally, the field of NLP continues to evolve, paving the way for future developments and enhancements. Here’s an exploration of both its limitations and the promising future developments:
Limitations of the Universal Sentence Encoder
- Semantic Complexity: Challenges capturing highly nuanced or abstract semantic meanings within sentences.
- Domain Specificity: May not excel in domain-specific contexts without fine-tuning or specialized training data.
- Contextual Ambiguity: Struggles with resolving ambiguities or multiple interpretations within sentences.
Future Developments and Enhancements
- Enhanced Semantic Understanding: Advancements in neural architectures for improved semantic representation and understanding.
- Domain Adaptation: Further developments in domain adaptation techniques, enhancing performance in specialized contexts without extensive fine-tuning.
- Multimodal Integration: Integration of visual and textual information for a more comprehensive understanding of context and semantics.
- Continual Learning: Implementations allowing continual learning to adapt to evolving language patterns and context changes.
- Reduced Dimensionality Models: Development of more efficient models with reduced dimensionality while maintaining semantic richness.
Best Practices and Practical Tips for Implementing a Universal Sentence Encoder
Maximizing the potential of the Universal Sentence Encoder (USE) requires adherence to best practices and thoughtful utilization strategies. Here’s a compilation of tips and best practices to ensure effective implementation and usage:
1. Data Preparation and Input Handling
- Clean and Preprocess Data: Ensure data cleanliness and preprocess text to enhance the quality of embeddings.
- Handle Variable-Length Sentences: Manage variable-length sentences efficiently for uniform embeddings.
2. Understanding Semantic Context
- Contextual Understanding: Grasp the model’s limitations in understanding highly nuanced or ambiguous contexts.
- Review Model Output: To gauge their understanding and contextual representations, evaluate model outputs.
3. Fine-tuning and Transfer Learning
- Fine-tuning Guidance: Explore fine-tuning options for domain-specific applications to enhance performance.
- Transfer Learning Consideration: Carefully consider transfer learning strategies, ensuring compatibility with specific use cases.
4. Evaluation and Performance Metrics
- Evaluate Semantic Similarity: Employ appropriate evaluation metrics to assess semantic similarity or relevance.
- Performance Benchmarking: Benchmark performance against baseline models or existing benchmarks for comparison.
5. Ethical Considerations and Bias Mitigation
- Bias Assessment: Scrutinize training data for biases and implement mitigation strategies to ensure fairness.
- Ethical AI Compliance: Adhere to ethical guidelines and standards for responsible AI implementation.
6. Documentation and Collaboration
- Thorough Documentation: Maintain comprehensive documentation of model versions, training data, and implementation details.
- Collaborative Approach: Foster collaboration among team members to leverage diverse expertise and insights.
7. Model Maintenance and Updates
- Regular Model Evaluation: Continuously evaluate model performance and retrain or update models as needed.
- Stay Updated: Keep abreast of advancements in NLP research and update models to incorporate new techniques or improvements.
8. Testing and Validation
- Robust Testing Procedures: Implement thorough testing methodologies to ensure robustness and reliability.
- Validation and Cross-validation: Employ validation techniques for model validation and cross-validation to ascertain performance consistency.
Adhering to these best practices fosters effective utilization of the Universal Sentence Encoder, promoting its accurate and ethical application across diverse domains and applications in natural language processing.
Conclusion
The Universal Sentence Encoder (USE) is a beacon of innovation in natural language processing, reshaping the landscape of machine understanding of textual data. Its ability to encapsulate semantic richness within fixed-length vectors has unlocked a realm where machines interpret language with a depth and context akin to human comprehension.
From its foundational neural architecture to its applications across diverse industries, the USE signifies a monumental leap in the quest for AI-driven semantic understanding. Its versatility across languages, nuanced semantic capture, and role as a transfer learning catalyst underscore its significance in empowering NLP systems.
While the USE heralds a new era in language understanding, acknowledging its limitations, ethical considerations, and the need for continual advancements is paramount. As the field of NLP evolves, embracing responsible AI practices, mitigating biases, and democratizing access to advanced models will shape a future where language comprehension within AI systems is robust and ethical.
As developers, researchers, and stakeholders traverse this transformative journey, the Universal Sentence Encoder is a testament to the ever-evolving synergy between human language and machine understanding. Its potential lies in its technical prowess and ability to pave the way for AI systems that genuinely comprehend the semantic fabric of our linguistic expressions. Embracing this journey of innovation and responsible utilization ensures that the USE continues to catalyse groundbreaking advancements in natural language processing.












0 Comments