What is Ordinary Least Squares (OLS)?
Ordinary Least Squares (OLS) is a fundamental technique in statistics and econometrics used to estimate the parameters of a linear regression model. In simple terms, OLS helps us find the best-fitting straight line through a set of data points by minimising the sum of the squared differences between the observed values and the values predicted by the line. This method is widely used because of its simplicity and efficiency in analysing variables’ relationships.
Table of Contents
This blog post aims to provide a beginner-friendly introduction to Ordinary Least Squares (OLS) regression. Whether you’re a student just starting in statistics, a data analyst looking to refresh your knowledge, or someone curious about how linear regression works, this guide will walk you through the essential concepts, the mathematics behind OLS, and its practical applications. By the end of this post, you’ll have a solid understanding of OLS and how it is used to make informed decisions based on data.
The Basics of Linear Regression
Understanding Linear Relationships
A linear relationship is one in which two variables move consistently and proportionately. In other words, as one variable changes, the other variable changes at a constant rate. This relationship can be visualised as a straight line plotted on a graph. For example, consider the relationship between the number of hours studied and exam scores: typically, more study hours lead to higher scores, illustrating a positive linear relationship. Understanding this concept is crucial because linear regression assumes that the relationship between the dependent and independent variables is linear.

Introduction to the Linear Regression Model
Linear regression is a statistical method to model the relationship between a dependent variable and one or more independent variables. The simplest form of linear regression, known as simple linear regression, involves just one independent variable. The following equation can express the linear regression model:
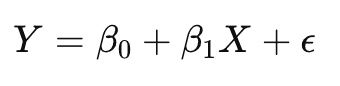
Where:
- Y represents the dependent variable (the outcome you’re trying to predict).
- X represents the independent variable (the predictor or input variable).
- β0 is the intercept of the regression line, which indicates where the line crosses the y-axis when X is zero.
- β1 is the slope of the regression line, which measures the change in Y for a one-unit change in X.
- ϵ is the error term, representing the difference between the observed and predicted values of Y.
This equation forms the backbone of linear regression analysis, where the goal is to find the values of β0 and β1 that best describe the relationship between X and Y. By fitting a straight line to the data, linear regression helps us understand how the dependent variable changes as the independent variable changes, making it a powerful tool for prediction and analysis.
Ordinary Least Squares (OLS) Explained
Definition of Ordinary Least Squares (OLS) in the Context of Linear Regression
Ordinary Least Squares (OLS) are used in linear regression to estimate the parameters of the linear relationship between the dependent and independent variables. Specifically, OLS is employed to determine the values of the coefficients β0 (intercept) and β1 (slope) in the linear regression equation. The essence of OLS lies in its objective: to minimise the differences between the observed data points and the values predicted by the linear model. In statistical terms, these differences are called residuals, and OLS works by minimising the sum of the squared residuals.
The Objective of Ordinary Least Squares (OLS)
The primary goal of OLS is to find the “best fit” line for a given set of data points. The “best fit” is the line that results in the smallest possible sum of the squared differences between the observed and predicted values. This process ensures that the predicted values are as close as possible to the actual values, on average.

Mathematically, the objective of OLS can be expressed as minimising the sum of squared residuals:

Where:
- Yi represents the observed value of the dependent variable for the i-th data point.
- Y^i represents the predicted value of the dependent variable for the iii-th data point, calculated using the regression line.
- nnn is the total number of observations.
By minimising this sum, OLS ensures that the overall error in the model is as small as possible, providing the most accurate and reliable estimates for the coefficients β0 and β1.
The “Best Fit” Line
The result of the OLS process is a straight line that best represents the relationship between the independent variable X and the dependent variable Y. This line can be used to make predictions about Y based on new values of X. For instance, if you were to use OLS to analyse the relationship between hours studied and exam scores, the “best fit” line would allow you to predict an exam score for any given number of study hours.
OLS is a foundational method in regression analysis due to its simplicity, efficiency, and intuitive understanding of the relationships between variables. Its ability to produce unbiased estimates under certain assumptions makes it a widely used tool in various fields, from economics to machine learning.
The Mathematics Behind Ordinary Least Squares (OLS)
Deriving the OLS Estimators
To understand how Ordinary Least Squares (OLS) works, it is essential to delve into the mathematical process of estimating the coefficients β0 (intercept) and β1 (slope) in the linear regression model. The goal is to find the values of β0 and β1 that minimise the sum of the squared differences between the observed values Yi and the predicted values Y^i.
The linear regression model can be expressed as:

Where:
- Yi is the observed value of the dependent variable for the i-th observation.
- Xi is the observed value of the independent variable for the i-th observation.
- ϵi is the error term for the i-th observation.
The predicted value Y^i is given by:

The residual for each observation is the difference between the observed and predicted values:

OLS aims to minimise the sum of squared residuals (SSR):

Expanding this, we get:

To find the OLS estimators for β0 and β1, we take partial derivatives of the sum of squared residuals concerning β0 and β1 and set them to zero. This process leads to the normal equations:

Solving these equations, we obtain the OLS estimators:

Where:
- Xˉ is the mean of the independent variable X.
- Yˉ is the mean of the dependent variable Y.
Interpretation of the Ordinary Least Squares (OLS) Estimators
The coefficients β^0and β^1 derived from the OLS process have specific interpretations:
- β^0 (Intercept): This is the estimated value of Y when X=0. It represents the point where the regression line crosses the y-axis. In many real-world situations, the intercept may not have a meaningful interpretation, especially if the independent variable X cannot realistically be zero (e.g., hours of study).
- β^1\ (Slope): This represents the estimated change in Y for a one-unit increase in X. In other words, it quantifies the relationship between the independent and dependent variables. For example, if X is hours studied and Y is exam scores, β^1 tells us how much the exam score is expected to increase for each additional hour of study.
Visualising the OLS Solution
The OLS solution can be visualised as finding the line that minimises the vertical distances (residuals) between the observed data points and the line itself. By minimising these squared distances, OLS ensures that the overall error in predicting Y based on X is as small as possible. This “best fit” line can be used to make predictions and analyse the strength and direction of the relationship between variables.
Understanding the mathematics behind OLS provides insight into how the method works and enhances one’s ability to interpret and apply linear regression analysis in real-world situations.
The 5 Primary Assumptions of Ordinary Least Squares (OLS)
Ordinary Least Squares (OLS) regression is a powerful tool, but its effectiveness hinges on several key assumptions. These assumptions ensure that the OLS estimators are unbiased, efficient, and consistent. Violating these assumptions can lead to incorrect conclusions and unreliable predictions. Here, we discuss the five primary assumptions underlying OLS.
Linearity
The first assumption is that the relationship between the independent variable(s) and the dependent variable is linear. This means that the dependent variable Y is a linear function of the independent variable(s) X. Mathematically, this is represented as:
If the true relationship is not linear (e.g., quadratic, logarithmic), the OLS model will not capture it accurately, leading to biased estimates. Ensuring linearity can be done by examining scatter plots or using transformations to linearise the relationship.
Independence
The second assumption is that the observations are independent of each other. This means that the value of the dependent variable for one observation is not influenced by the value of the dependent variable for another observation. This assumption is fundamental in time series data, where observations may be autocorrelated, or in clustered data, where observations within clusters may be correlated.
If independence is violated, the standard errors of the OLS estimates may be incorrect, leading to invalid inference. Techniques like clustered standard errors or time-series models can address this issue.
Homoscedasticity
Homoscedasticity refers to the assumption that the variance of the error terms ϵ is constant across all levels of the independent variable(s) X. In other words, the spread or “noise” of the errors does not change as the value of X changes.
When this assumption is violated (a condition known as heteroscedasticity), the OLS estimators remain unbiased. Still, they are no longer efficient, and the standard errors are inconsistent, leading to unreliable hypothesis tests. Detecting heteroscedasticity can be done using plots of residuals versus fitted values or statistical tests like the Breusch-Pagan test. Remedies include using robust standard errors or transforming the data.
No Perfect Multicollinearity
The fourth assumption is that the independent variables do not have perfect multicollinearity. Multicollinearity occurs when two or more independent variables are highly correlated, making it difficult to isolate the individual effect of each variable on the dependent variable.
Perfect multicollinearity implies that one independent variable is an exact linear function of another. This leads to infinite standard errors and indeterminate coefficients, meaning the OLS model cannot provide unique estimates for the coefficients. Detecting multicollinearity can be done using the Variance Inflation Factor (VIF) or correlation matrices. To address multicollinearity, one might consider removing or combining correlated variables.
Normality of Errors
The final assumption is that the error terms ϵ are normally distributed (Gaussian distribution). This assumption is crucial for conducting valid hypothesis tests and constructing confidence intervals. While the OLS estimators are still unbiased and consistent even if the errors are not normally distributed, the standard errors and p-values will be unreliable.

This assumption is fundamental in small sample sizes. As sample sizes grow larger, the Central Limit Theory suggests that the distribution of the OLS estimators will approach normality, even if the errors are not standard. Normality can be assessed using Q-plots or statistical tests like the Shapiro-Wilk test. If normality is violated, transaction or alternative estimation methods (e.g., bootstrapping) can be used.
How to Implement Ordinary Least Squares (OLS) in Practice With Examples
Implementing Ordinary Least Squares (OLS) in practice involves several steps, from collecting and preparing your data to running the regression analysis and interpreting the results. Here’s a step-by-step guide on how to apply OLS regression to your data.
Define the Problem and Identify Variables:
Start by clearly defining the problem you want to solve. Identify the dependent variable (the outcome you want to predict) and the independent variable(s) (the predictors).
For example, if you want to predict house prices (dependent variable) based on features like square footage and number of bedrooms (independent variables), make sure these variables are clearly defined.
Gather Data:
Collect the necessary data for both your dependent and independent variables. This data could come from surveys, experiments, or existing datasets. Ensure that the data is relevant, reliable, and of sufficient size to produce meaningful results.
Ensure your data is clean and free from errors, outliers, or missing values that could distort your analysis.
Performing OLS Regression with Software
Once your data is ready, you can perform OLS regression using various software tools. Below is a general guide to performing OLS in some commonly used tools.
Ordinary Least Squares Using Python (Statsmodels)
Step 1: Import Libraries and Load Data
import pandas as pd
import statsmodels.api as sm
# Load your dataset
data = pd.read_csv('your_data.csv')Step 2: Define the Dependent and Independent Variables
X = data['independent_variable'] # Replace with your independent variable
Y = data['dependent_variable'] # Replace with your dependent variable
X = sm.add_constant(X) # Adds a constant term to the predictorStep 3: Fit the OLS Model
model = sm.OLS(Y, X).fit()Step 4: View the Results
print(model.summary())Ordinary Least Squares Using R
Step 1: Load Data
data <- read.csv("your_data.csv")Step 2: Perform OLS Regression
model <- lm(dependent_variable ~ independent_variable, data=data)Step 3: View the Results
summary(model)Ordinary Least Squares Using Excel
Step 1: Input Data
Enter your dependent and independent variables into separate columns.
Step 2: Run the Regression Analysis
Go to the “Data” tab and select “Data Analysis.” From the list of tools, choose “Regression.”
Step 3: Set Up the Regression
Define the Input Y Range (dependent variable) and Input X Range (independent variable).
Check the “Labels” box if your data has headers.
Step 4: Interpret the Output
Excel will provide the regression coefficients, R-squared value, and other statistics in a new sheet.
Interpreting the Results
After running the OLS regression, you’ll receive an output that contains several key metrics and statistics. Understanding these outputs is crucial for making informed decisions based on your analysis.
- Coefficients (β^0and β^1):
- β^0 (Intercept): Represents the expected value of the dependent variable when all independent variables are zero. While it may not always be meaningful in isolation, it’s important for predicting values.
- β^1 (Slope): Represents the change in the dependent variable for a one-unit change in the independent variable. A positive slope indicates a positive relationship, while a negative slope indicates a negative relationship.
- R-squared (R²):
- R-squared measures the proportion of variance in the dependent variable that can be explained by the independent variable(s). It ranges from 0 to 1, with higher values indicating a better fit. However, a high R-squared does not always imply that the model is appropriate, especially if other assumptions are violated.
- P-values:
- The p-value tests the hypothesis that the coefficient is equal to zero (no effect). A low p-value (typically < 0.05) indicates that you can reject the null hypothesis, suggesting that the independent variable is a significant predictor of the dependent variable.
- Standard Errors:
- Standard errors provide an estimate of the variability of the coefficient estimates. Smaller standard errors indicate more precise estimates.
- Confidence Intervals:
- Confidence intervals provide a range within which the true coefficient value will likely fall. A 95% confidence interval means that if you repeat the analysis many times, 95% of the intervals would contain the true coefficient value.
Making Predictions
Once you’ve interpreted the results, you can use the OLS model to make predictions. Given new values of the independent variable(s), you can plug them into the regression equation to estimate the dependent variable. For example:

This equation can be used to predict future outcomes or to understand the impact of different scenarios.
Checking Model Assumptions and Diagnostics
To ensure the validity of your OLS model, it’s essential to check the assumptions discussed earlier:
- Linearity: Plot the observed vs. predicted values or residuals vs. predicted values to check for linearity.
- Independence: Verify that the data collection process or the study design ensures independence.
- Homoscedasticity: Plot the residuals against predicted values. The spread should be constant.
- Multicollinearity: Check each independent variable’s Variance Inflation Factor (VIF).
- Normality of Errors: Use Q-Q plots or statistical tests to check if the residuals are normally distributed.
If assumptions are violated, consider transforming the data, adding interaction terms, or using robust regression techniques.
Implementing OLS in practice involves careful data collection, appropriate software tools, and a thorough interpretation of the results. Following these steps and ensuring the fundamental assumptions are met, you can confidently apply OLS regression to analyse relationships between variables and make informed predictions.
Common Pitfalls and How to Avoid Them
While Ordinary Least Squares (OLS) regression is a powerful tool for statistical analysis, several common pitfalls can undermine the validity of your results. Being aware of these pitfalls and knowing how to avoid them is crucial for accurate and reliable analysis.
Overfitting
Overfitting occurs when your model becomes too complex, capturing the underlying relationship between the variables and the noise in the data. This typically happens when you include too many independent variables or the model fits the training data too closely.

Symptoms:
- High R-squared value in the training data but poor performance on new, unseen data.
- Very small p-values for almost all predictors suggest they are all significant.
How to Avoid:
- Simplify the Model: Use fewer independent variables, focusing on those with theoretical solid justification or high correlation with the dependent variable.
- Cross-Validation: Split your data into training and testing sets, or use k-fold cross-validation to ensure your model generalises well to unseen data.
- Regularisation Techniques: Consider using methods like Ridge or Lasso regression, which can penalise overly complex models and prevent overfitting.
Multicollinearity
Multicollinearity arises when two or more independent variables in the model are highly correlated. This makes it difficult to isolate the individual effect of each variable on the dependent variable, leading to inflated standard errors and unstable coefficient estimates.
Symptoms:
- High Variance Inflation Factor (VIF) values (typically above 10).
- Unexpected signs or magnitudes of regression coefficients.
- Large changes in coefficient estimates when a variable is added or removed.
How to Avoid:
- Check VIF: Regularly check the VIF for each variable. If it is too high, consider removing or combining correlated variables.
- Principal Component Analysis (PCA): Use PCA or other dimensionality reduction techniques to transform correlated variables into smaller uncorrelated components.
- Centring Variables: For interaction terms or polynomial regression, centring the variables (subtracting the mean) can help reduce multicollinearity.
Heteroscedasticity
Heteroscedasticity occurs when the variance of the error terms is not constant across all levels of the independent variable(s). This violates one of the key OLS assumptions, leading to inefficient estimates and unreliable standard errors and affecting hypothesis testing.
Symptoms:
- A funnel shape or pattern in a plot of residuals versus fitted values.
- Significant results in formal tests for heteroscedasticity, such as the Breusch-Pagan test or White’s test.
How to Avoid:
- Transform the Data: To stabilise variance, apply a logarithmic or square root transformation.
- Use Robust Standard Errors: Employ robust standard errors less sensitive to heteroscedasticity.
- Weighted Least Squares (WLS): If heteroscedasticity is severe, consider using WLS, which gives different weights to observations based on the variance of their errors.
Omitted Variable Bias
Omitted variable bias occurs when a relevant independent variable is left out of the model. This leads to biased and inconsistent estimates of the coefficients for the included variables, which can distort the true relationship between the variables.
Symptoms:
- Coefficient estimates that seem too high or too low compared to theoretical expectations.
- A coefficient change is significant when a previously omitted variable is added to the model.
How to Avoid:
- Theoretical Justification: Ensure that all relevant variables based on theory or prior research are included in the model.
- Model Specification Tests: Use tests like the Ramsey RESET test to check for model misspecification.
- Sensitivity Analysis: Compare results with and without certain variables to detect potential bias.
Misinterpreting Coefficients
Misinterpreting the meaning of regression coefficients, especially in interaction terms, logarithmic transformations, or when working with dummy variables, can lead to incorrect conclusions.
Symptoms:
- Treating the coefficient of a dummy variable as a continuous effect.
- Misunderstanding the percentage interpretation in log-transformed models.
- Ignoring the interaction effects between variables.
How to Avoid:
- Careful Interpretation: Ensure you understand each coefficient’s context and mathematical meaning. For example, in a log-linear model, the coefficients represent percentage changes.
- Interaction Terms: Interpret the effect of interaction terms as they represent the combined effect of two or more variables.
- Training and Resources: Continuously educate yourself on regression techniques and best practices using resources such as textbooks, online courses, and peer-reviewed articles.
Ignoring Model Diagnostics
Failing to check model diagnostics can lead to undetected problems that invalidate the results. Diagnostics help to identify issues like non-linearity, influential outliers, or violations of OLS assumptions.
Symptoms:
- Unexpectedly high or low R-squared values.
- Residual plots showing non-random patterns or extreme outliers.
- Inconsistent results when comparing different models.
How to Avoid:
- Residual Analysis: Regularly plot and analyse residuals to check for non-linearity, outliers, or heteroscedasticity.
- Influential Points: Use diagnostic measures like Cook’s distance to identify and potentially exclude influential data points disproportionately affecting the model.
- Model Comparison: Compare your model with alternative specifications to ensure robustness and reliability.
By being mindful of these common pitfalls and applying the appropriate checks and remedies, you can significantly enhance the reliability and accuracy of your OLS regression analysis. Proper model building, thorough diagnostics, and careful interpretation of results are essential for leveraging the full power of OLS in practical applications.
Applications of Ordinary Least Squares (OLS)
Ordinary Least Squares (OLS) regression is a versatile tool used in various fields to model relationships between variables, make predictions, and infer causal relationships. Its simplicity and effectiveness make it applicable in many domains. Here are some common applications of OLS across different disciplines:
Economics
1. Demand and Supply Estimation:
- OLS is often used to estimate demand and supply functions. For instance, economists might model the relationship between the price of a good and the quantity demanded, controlling for other factors like income and preferences.
- Example: Estimating the price elasticity of demand by regressing the quantity demanded based on price and other variables.
2. Wage Determination:
- Economists use OLS to analyse how education, experience, and skills impact wages. This helps understand labour market dynamics and the return on investment in education.
- Example: Estimating the returns to education by regressing wages on years of schooling and work experience.
3. Economic Growth Analysis:
- OLS can explore economic growth determinants by regressing GDP growth rates on factors like investment, human capital, and institutional quality.
- Example: Understanding the impact of government policy on economic growth by analysing cross-country or time-series data.
Finance
1. Capital Asset Pricing Model (CAPM):
- In finance, OLS estimates the beta coefficient in the CAPM, which measures a stock’s volatility relative to the overall market. This helps investors assess the risk associated with a particular stock.
- Example: Estimating a stock’s beta by regressing its returns on the market index returns.
2. Risk and Return Analysis:
- OLS analyses the relationship between risk factors (e.g., market risk, credit risk) and asset returns. This helps in portfolio management and risk assessment.
- Example: Modeling the effect of macroeconomic variables on bond yields.
3. Forecasting Financial Variables:
- Financial analysts use OLS to predict the future values of key financial indicators, such as stock prices, interest rates, and exchange rates, based on historical data.
- Example: Predicting future stock prices using historical prices and trading volume data.
Social Sciences
1. Public Health Research:
- OLS is widely used in public health to assess the impact of various factors (e.g., socioeconomic status, lifestyle choices) on health outcomes like life expectancy, disease prevalence, or access to healthcare.
- Example: Analysing the effect of smoking on lung cancer incidence by regressing incidence rates on smoking rates and other health-related variables.
2. Education Studies:
- In education research, OLS helps understand how teacher quality, class size, and school funding affect student performance.
- Example: Estimating the impact of class size on student test scores by controlling for other variables like socioeconomic status.
3. Crime Rate Analysis:
- Sociologists use OLS to study the determinants of crime rates, examining the influence of variables such as poverty, unemployment, and education levels.
- Example: Modeling the relationship between unemployment rates and crime rates in urban areas.
Marketing
1. Sales Forecasting:
- Marketers use OLS to predict future sales based on historical sales data and factors such as advertising expenditures, seasonality, and market trends.
- Example: Estimating the effect of advertising spend on sales by regressing sales on advertising spend and other marketing efforts.
2. Consumer Behavior Analysis:
- OLS helps understand consumer preferences by modelling the relationship between consumer characteristics (e.g., age, income, preferences) and purchasing behaviour.
- Example: Analysing how consumer income affects the choice between premium and budget products.
3. Pricing Strategy:
- Companies use OLS to determine optimal pricing strategies by analysing how price changes impact demand and revenue.
- Example: Estimating the price elasticity of demand for a product to guide pricing decisions.
Engineering and Natural Sciences
1. Quality Control and Process Optimisation:
- Engineers use OLS to analyse the relationship between input variables (e.g., temperature, pressure, material properties) and output quality in manufacturing processes.
- Example: Optimising a manufacturing process by regressing defect rates on various parameters.
2. Environmental Modeling:
- OLS is used to model environmental phenomena, such as the relationship between pollution levels and weather patterns or the impact of human activities on biodiversity.
- Example: Modeling the effect of industrial emissions on local air quality by regressing pollution levels on emission sources and weather variables.
3. Reliability Engineering:
- In reliability engineering, OLS can help predict the lifespan of components or systems by analysing the relationship between failure rates and factors like stress or usage.
- Example: Estimating the failure rate of mechanical components based on operational stress data.
OLS regression is a foundational tool that finds applications in various fields, from economics and finance to social sciences, marketing, and engineering. Its ability to model relationships, make predictions, and infer causal effects makes it indispensable for researchers, analysts, and decision-makers. By understanding and leveraging Ordinary Least Squares in these various contexts, professionals can gain valuable insights, optimise processes, and drive informed decision-making.
Conclusion
Ordinary Least Squares (OLS) regression is a cornerstone of statistical analysis, offering a powerful and straightforward method for modelling relationships between variables. Whether you’re in economics, finance, social sciences, marketing, or engineering, OLS provides a versatile framework for understanding complex data, making predictions, and deriving actionable insights.
Throughout this discussion, we’ve explored the fundamentals of Ordinary Least Squares, from the underlying mathematics and assumptions to practical implementation and common pitfalls. We’ve also highlighted the wide range of applications where OLS is invaluable, showcasing its adaptability across different fields.
However, like any analytical tool, OLS’s effectiveness depends on careful application. Ensuring that the key assumptions are met, interpreting results accurately, and avoiding common pitfalls are crucial for obtaining reliable and meaningful outcomes. When applied correctly, OLS regression not only helps explain existing patterns but also equips decision-makers with the tools to predict future trends and make informed choices.
In an increasingly data-driven world, mastering OLS regression empowers professionals to unlock the full potential of their data. It provides a solid foundation for analysis that can be built upon with more advanced techniques as needed. Whether tackling a business problem, conducting academic research, or optimising a process, OLS remains an essential tool in your analytical toolkit.












0 Comments