What is a Bayesian Network?
Bayesian network, also known as belief networks or Bayes nets, are probabilistic graphical models representing random variables and their conditional dependencies via a directed acyclic graph (DAG). They are named after the Reverend Thomas Bayes, an 18th-century mathematician, and are widely used in various fields, including artificial intelligence, machine learning, statistics, and decision analysis.
Table of Contents
At its core, a Bayesian network consists of two main components:
- Graphical Structure: The network’s structure is represented by a directed acyclic graph (DAG) where nodes represent random variables, and directed edges represent probabilistic dependencies between variables. A directed edge from node A to node B indicates that node B is conditionally dependent on node A.
- Conditional Probability Tables (CPTs): Associated with each node in the graph are conditional probability tables, which specify the probability distribution of a node given its parent nodes in the graph. These tables quantify how the probability of a node’s value changes based on the values of its parent nodes.

Bayesian networks provide a powerful framework for modelling uncertainty and reasoning under uncertainty. They allow for efficient inference, which is the process of computing probabilities of variables given observed evidence and learning from data.
Key features and characteristics of Bayesian networks include:
- Modularity: The modular structure of Bayesian networks allows for the representation of complex systems by decomposing them into simpler components, making them easier to understand and manage.
- Causal Reasoning: The directed edges in Bayesian networks encode causal relationships between variables, enabling reasoning about the effects of interventions and actions.
- Uncertainty Handling: Bayesian networks are well-suited for representing and reasoning with uncertain information. They can handle incomplete or noisy data and provide a principled framework for updating beliefs in the light of new evidence.
- Efficient Inference: Despite the combinatorial explosion of possible states in large networks, efficient algorithms exist for performing inference tasks such as computing marginal probabilities, conditional probabilities, and most probable explanations.
- Learning from Data: Bayesian networks can be learned from data, either by estimating the parameters of the network (parameter learning) or by discovering the network’s structure (structure learning) from observed data.
Applications of Bayesian networks span a wide range of domains, including healthcare (medical diagnosis, prognosis), finance (risk assessment, portfolio management), natural language processing (language modelling, information retrieval), robotics (sensor fusion, autonomous systems), and more.
In summary, Bayesian networks provide a powerful framework for modelling uncertain domains, reasoning under uncertainty, and making informed decisions based on probabilistic dependencies between variables. They offer a versatile tool for representing and reasoning about complex systems in various real-world applications.
Foundations of Probability Theory
Introduction to Probability Theory
Probability theory is the mathematical framework for quantifying uncertainty and reasoning about randomness. In this section, we’ll delve into the fundamental concepts of probability theory.
Definition of Probability
Probability is a measure of the likelihood of an event occurring. It is expressed as a value between 0 and 1, where 0 indicates impossibility and 1 indicates certainty.
For example, the probability of rolling a 6 in a fair six-sided die is 1/6, denoted as P(6) = 1/6.

Basic Concepts
- Sample Space:
- The sample space, denoted by S, represents the set of all possible outcomes of a random experiment.
- Example: For a coin toss, the sample space is S={H, T}, where H represents heads and T represents tails.
- Events:
- An event is any subset of the sample space representing a particular outcome or a combination of outcomes.
- Example: The event of rolling an even number with a fair six-sided die is E={2,4,6}.
- Outcomes:
- Outcomes are the individual elements of the sample space, representing the result of a random experiment.
- Example: In a coin toss, the possible outcomes are heads (H) and tails (T).
Understanding Probability Distributions
A probability distribution describes the likelihood of each possible outcome of a random variable.
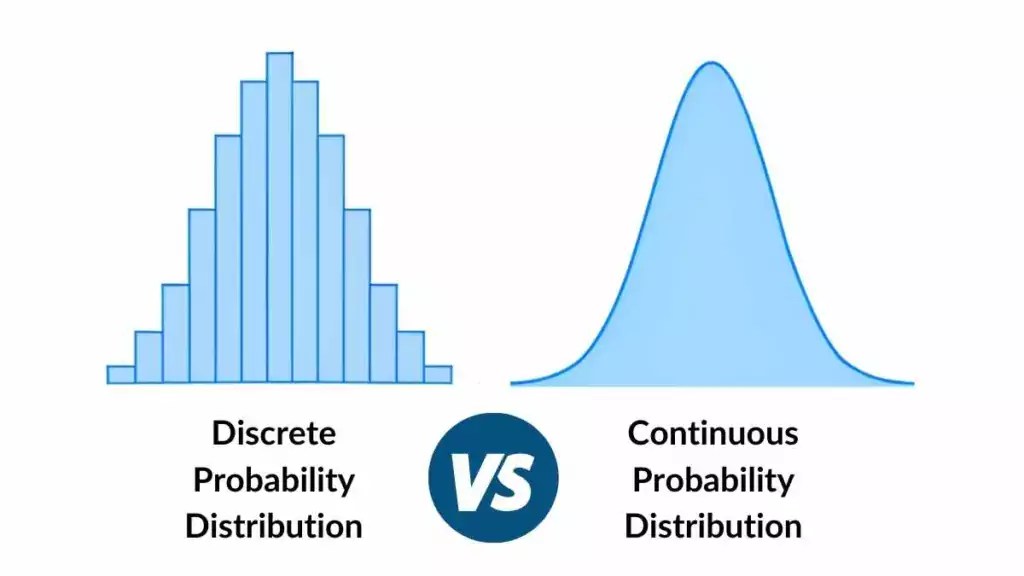
- Discrete Probability Distribution:
- Assigns probabilities to each possible value of a discrete random variable.
- Example: Probability mass function (PMF) for a fair six-sided die assigns a probability of 1/6 to each outcome.
- Continuous Probability Distribution:
- Assigns probabilities to intervals of values of a continuous random variable.
- Example: Normal distribution describes many natural phenomena such as heights or weights.
Probability theory forms the foundation for building Bayesian networks and other probabilistic models. By understanding the basic concepts of probability, we can effectively model uncertainty and make informed decisions in various fields of study.
Conditional Probability and Bayes’ Theorem
Conditional probability and Bayes’ theorem are crucial in quantifying the likelihood of events given certain conditions. In this section, we’ll explore these concepts in detail.
Definition of Conditional Probability
Conditional probability measures the likelihood of an event occurring, given that another event has already happened.
Mathematically, the conditional probability of event A given event B is denoted as P(A∣B), and it is calculated as the probability of the intersection of A and B divided by the probability of B.
Formula: P(A∣B)=P(B)P(A∩B)
Bayes’ Theorem
Bayes’ theorem provides a way to revise or update probabilities based on new evidence.
It establishes a relationship between conditional probabilities regarding reversing the conditioning order.
Mathematically, Bayes’ theorem states:
P(A∣B)=(P(B∣A)⋅P(A))/P(B) where:
- P(A∣B) is the posterior probability of event A given event B.
- P(B∣A) is the likelihood of observing event B, given event A.
- P(A) and P(B) are the prior probabilities of events A and B, respectively.
Application of Bayes’ Theorem
- Bayes’ theorem is widely used in various fields, including statistics, machine learning, and artificial intelligence.
- It serves as the foundation for Bayesian inference, allowing us to update our beliefs about hypotheses in light of new evidence.
- Example: Medical diagnosis, where Bayes’ theorem helps calculate the probability of a disease given the observed symptoms.
Interpretation of Bayes’ Theorem
- Bayes’ theorem provides a principled way to update beliefs by combining prior knowledge with new evidence.
- It highlights the importance of prior beliefs and observed data in making informed decisions.
- Bayes’ theorem facilitates rational decision-making in uncertain situations by quantifying the impact of new information on existing beliefs.
Understanding conditional probability and Bayes’ theorem is essential for reasoning under uncertainty and making optimal decisions based on available evidence. These concepts form the basis of Bayesian inference, widely used in probabilistic modelling and decision-making processes.
Joint Probability Distributions
Joint probability distributions provide a comprehensive way to model the relationships between multiple random variables. In this section, we’ll explore the concept of joint probability distributions and their significance in probabilistic modelling.
Definition of Joint Probability Distributions
A joint probability distribution describes the simultaneous occurrence of multiple random variables.
For n random variables 1,2,…, X1, X2,…, Xn, the joint probability distribution specifies the probability of each possible combination of values for these variables.
It provides a complete representation of the uncertainty associated with the entire set of random variables.
Multivariate Probability Distributions
- Discrete Joint Probability Distributions:
- The joint probability distribution is a table or function that assigns probabilities to each combination of possible values for discrete random variables.
- Example: Consider two dice rolls. The joint probability distribution specifies the probabilities of obtaining each possible pair of outcomes (e.g., (1, 1), (1, 2), …, (6, 6)).
- Continuous Joint Probability Distributions:
- A probability density function (PDF) or cumulative distribution function (CDF) represents the joint probability distribution distribution for continuous random variables.
- Example: In the case of two continuous random variables representing height and weight, the joint probability distribution describes the probability density across the range of possible height-weight pairs.

Properties of Joint Probability Distributions
- Marginal Probabilities:
- Marginal probabilities refer to the probabilities of individual random variables without considering the values of other variables.
- They can be obtained by summing or integrating the joint probabilities over the values of the other variables.
- Conditional Probabilities:
- Conditional probabilities express the likelihood of specific outcomes of one variable given particular values of other variables.
- They can be derived from the joint probability distribution using conditional probability rules.
Representation of Joint Probabilities
- Tabular Representation:
- For a small number of discrete random variables, joint probabilities can be conveniently represented in tabular form.
- Functional Representation:
- For many variables or continuous random variables, joint probabilities are often represented using mathematical functions such as PDFs or CDFs.
Joint probability distributions are the foundation for probabilistic modelling in various domains, allowing us to capture complex relationships between multiple variables. Understanding joint probability distributions is essential for constructing accurate probabilistic models and performing inference tasks such as marginalization and conditional probability calculation.
Independence and Conditional Independence
Independence and conditional independence are essential concepts in probability theory that describe the relationships between random variables. This section will explore these concepts and their implications in probabilistic modelling.
1. Independence of Events:
Two events, A and B, are said to be independent if the occurrence of one event does not affect the probability of the other event.
Mathematically, events A and B are independent if P(A∩B)=P(A)⋅P(B).
Independence implies that knowing the outcome of one event provides no information about the result of the other event.
2. Independence of Random Variables:
Similarly, random variables X and Y are independent if the joint probability distribution of X and Y factorizes into the product of their marginal probability distributions.
Mathematically, X and Y are independent if P(X=x,Y=y)=P(X=x)⋅P(Y=y) for all x and y.
Independence between random variables simplifies probabilistic modelling and inference, allowing us to factorize complex joint distributions into simpler components.
3. Conditional Independence:
Conditional independence extends the concept of independence to situations where the independence of two variables depends on the value of a third variable.
Random variables X and Y are conditionally independent given random variable Z if X and Y are independent for every value of Z.
Mathematically, X and Y are conditionally independent given Z if P(X=x, Y=y∣Z=z)=P(X=x∣Z=z)⋅P(Y=y∣Z=z) for all x, y, and z.
Conditional independence is a powerful concept in Bayesian networks, allowing for compact representations of complex dependency structures.
4. Implications of Independence:
Independence and conditional independence simplify probabilistic modelling by reducing the parameters needed to describe joint distributions.
These concepts enable efficient inference algorithms, allowing for the factorization of joint distributions and the decomposition of complex dependency structures.
Understanding independence and conditional independence is crucial for designing and interpreting Bayesian networks, where graphical structures encode these relationships.
Independence and conditional independence are fundamental concepts in probability theory that underlie many probabilistic models and inference techniques. We can construct efficient and accurate probabilistic models to represent complex real-world phenomena by identifying and exploiting these relationships.
Concept and Components of Bayesian Networks
Bayesian networks, also known as belief networks, are probabilistic graphical models representing probabilistic dependencies among a set of random variables using a directed acyclic graph (DAG). In this section, we’ll explore the concept of Bayesian networks and their key components.
Concept of Bayesian Networks
Bayesian networks provide a structured way to represent and reason about uncertain domains.
Using a graph structure, they model probabilistic dependencies between variables, where nodes represent random variables and directed edges represent direct dependencies or causal relationships between variables.
Graphical Structure
1. Nodes:
Nodes in a Bayesian network represent random variables or observable quantities in the domain being modelled.
Each node corresponds to a specific variable of interest, such as “Weather,” “Temperature,” or “Flu Status.”
2. Directed Edges:
Directed edges between nodes indicate direct dependencies or causal relationships between variables.
An arrow from node A to node B signifies that node B depends probabilistically on node A, given that A is a parent node of B.
3. Conditional Probability Tables (CPTs):
Associated with each node in a Bayesian network is a conditional probability table (CPT) that quantifies the probabilistic relationship between that node and its parent nodes.
The CPT specifies the conditional probability distribution of a node given the states of its parent nodes.
Each entry in the CPT represents the probability of a particular outcome of the node given specific combinations of outcomes of its parent nodes.

Example of a Bayesian network with nodes, edges, and CPTs.
Inference and Reasoning
- Bayesian networks enable efficient inference and reasoning under uncertainty.
- Given observed evidence or data, Bayesian networks can compute probabilities of unobserved variables, make predictions, and perform diagnostic reasoning.
- Inference algorithms such as variable elimination, belief propagation, and Markov Chain Monte Carlo (MCMC) commonly perform probabilistic reasoning in Bayesian networks.
Types of Graphical Models
1. Bayesian Networks (BNs):
- Bayesian networks, also known as belief networks, represent dependencies among variables using directed acyclic graphs (DAGs).
- Directed edges between nodes in the graph indicate direct probabilistic dependencies, with each node representing a random variable and each edge representing a conditional dependency.
- Bayesian networks are well-suited for representing causal relationships, performing inference, and reasoning under uncertainty.
2. Markov Networks:
- Markov networks, known as Markov random fields, represent dependencies among variables using undirected graphs.
- Nodes in a Markov network represent random variables, and edges represent pairwise interactions or dependencies between variables.
- Markov networks are widely used in applications such as image processing, computer vision, and spatial modelling.
Advantages of Graphical Models
- Graphical models provide a compact and intuitive representation of complex probabilistic relationships.
- They facilitate efficient inference and reasoning under uncertainty by exploiting the graph structure to factorize joint probability distributions.
- Graphical models enable principled approaches to learning probabilistic models from data, including parameter estimation and structure learning.
Applications of Bayesian Networks
- Bayesian networks find applications in various fields, including healthcare, finance, robotics, natural language processing, etc.
- Examples of applications include medical diagnosis, risk assessment, fault diagnosis, sentiment analysis, and autonomous systems.
Understanding the concept and components of Bayesian networks is essential for effectively modelling and reasoning about uncertain domains. Bayesian networks offer a versatile and intuitive framework for representing complex probabilistic relationships and making informed decisions based on available evidence.
Inference in a Bayesian Network
Inference in Bayesian networks refers to reasoning about the probabilities of unobserved variables given observed evidence or data. Bayesian networks provide a principled framework for performing inference efficiently and accurately. This section will explore various techniques and algorithms used for inference in Bayesian networks.
1. Belief Updating
The belief updating concept is at the core of Bayesian inference, where variables’ probabilities are revised based on observed evidence using Bayes’ theorem.
Given a Bayesian network B with variables X1, X2,…, Xn and observed evidence E, the posterior probability distribution P(Xi∣E) for each variable Xi can be computed.
2. Exact Inference Methods
- Variable Elimination:
- Variable elimination is a systematic algorithm for computing exact inference in Bayesian networks.
- It involves eliminating variables from the network by marginalizing them until the desired query variables are obtained.
- Variable elimination exploits the Bayesian network’s graph structure to reduce the inference’s computational complexity.
- Junction Tree Algorithm:
- The junction tree algorithm is another exact inference method that is particularly efficient for performing inference in Bayesian networks with loops or cycles.
- It constructs a junction tree, also known as a clique tree, from the Bayesian network’s graph structure and performs message passing to compute marginal probabilities.
3. Approximate Inference Methods
- Gibbs Sampling:
- Gibbs sampling is a Markov Chain Monte Carlo (MCMC) method used for approximate inference in Bayesian networks.
- It generates samples from the joint probability distribution of the variables in the network, allowing for approximate estimation of marginal probabilities.
- Belief Propagation:
- Belief propagation is an approximate inference algorithm based on message passing in Bayesian networks.
- It propagates belief messages between nodes in the graph, iteratively updating the probabilities of variables until convergence.
4. Importance Sampling
- Importance sampling is a general-purpose Monte Carlo method for approximating Bayesian networks’ marginal probabilities.
- It generates samples from a proposal distribution and assigns weights to each sample based on its likelihood under the target distribution, allowing for efficient estimation of probabilities.
Inference in Bayesian networks involves computing probabilities of unobserved variables given observed evidence or data. Exact inference methods such as variable elimination and junction tree algorithm provide accurate solutions, while approximate methods such as Gibbs sampling, belief propagation, and importance sampling offer efficient solutions for complex networks. Choosing the appropriate inference method depends on the network’s complexity and the desired accuracy level.
Learning Algorithms in a Bayesian Network
Learning Bayesian networks involves automatically constructing or updating the structure and parameters of a Bayesian network from data. This section explores techniques and algorithms for learning Bayesian networks from observed data.
1. Parameter Learning
- Maximum Likelihood Estimation (MLE):
- MLE is a commonly used method for estimating the parameters of a Bayesian network from data.
- It seeks the parameter values that maximize the likelihood of the observed data given the network structure.
- MLE involves counting the occurrences of different combinations of variable states in the data and normalizing them to obtain probabilities.
- Expectation-Maximization (EM) Algorithm:
- The EM algorithm is an iterative optimization technique for parameter learning in Bayesian networks.
- It alternates between an expectation (E) step, where the expected values of the latent variables are computed given the current parameters, and a maximization (M) step, where the parameters are updated to maximize the likelihood of the observed data.
2. Structure Learning
- Score-Based Structure Learning:
- Score-based methods aim to find the Bayesian network structure that maximizes a scoring metric based on the observed data.
- Common scoring metrics include the Bayesian Information Criterion (BIC), Akaike Information Criterion (AIC), and Minimum Description Length (MDL).
- Score-based structure learning algorithms search through the space of possible network structures to find the one that optimizes the chosen scoring metric.
- Constraint-Based Structure Learning:
- Constraint-based methods learn the structure of a Bayesian network by testing conditional independence relationships in the data.
- They use statistical tests such as chi-square tests or mutual information to determine which variables are conditionally independent given others.
- Constraint-based algorithms build the network structure incrementally by adding edges based on the conditional independence tests.
- Hybrid Structure Learning:
- Hybrid approaches combine score-based and constraint-based methods to learn Bayesian network structures.
- These methods typically start with an initial structure and iteratively refine it using local score-based adjustments and conditional independence tests.
3. Bayesian Model Averaging (BMA):
- BMA is a Bayesian approach to structure learning that considers multiple potential network structures and combines them using Bayesian model averaging.
- Given the observed data, it assigns probabilities to different network structures based on their posterior probabilities, allowing for uncertainty quantification in the learned structure.
Learning Bayesian networks from data is a challenging task involving parameter estimation and structure learning. Various algorithms and techniques, including maximum likelihood estimation, expectation-maximization, score-based, constraint-based, and Bayesian model averaging, offer approaches to automate this process and construct accurate Bayesian network models from observed data. The choice of learning method depends on factors such as the dataset’s size, the network’s complexity, and the desired level of interpretability and uncertainty modelling.
How To Implement a Bayesian Network in Python Example
To work with Bayesian networks in Python, you can use libraries such as pgmpy, which is a Python library for working with Probabilistic Graphical Models (PGMs), including Bayesian Networks (BNs), Markov Networks (MNs), and more. Below is a basic example of how to create and work with a Bayesian network using pgmpy:
pythonCopy code
# Install pgmpy if you haven't already
# !pip install pgmpy
from pgmpy.models import BayesianModel
from pgmpy.factors.discrete import TabularCPD
from pgmpy.inference import VariableElimination
# Define the structure of the Bayesian network
model = BayesianModel([('A', 'C'), ('B', 'C')])
# Define the conditional probability distributions (CPDs)
cpd_a = TabularCPD(variable='A', variable_card=2, values=[[0.6], [0.4]])
cpd_b = TabularCPD(variable='B', variable_card=2, values=[[0.7], [0.3]])
cpd_c = TabularCPD(variable='C', variable_card=2, values=[[0.1, 0.2, 0.3, 0.4], [0.9, 0.8, 0.7, 0.6]],
evidence=['A', 'B'], evidence_card=[2, 2])
# Add CPDs to the model
model.add_cpds(cpd_a, cpd_b, cpd_c)
# Check if the model is valid
print(model.check_model())
# Perform inference
inference = VariableElimination(model)
# Calculate the marginal probability of 'C' given evidence {'A': 0, 'B': 1}
result = inference.query(variables=['C'], evidence={'A': 0, 'B': 1})
print(result)Output:
+------+----------+
| C | phi(C) |
+======+==========+
| C(0) | 0.2000 |
+------+----------+
| C(1) | 0.8000 |
+------+----------+Make sure to install pgmpy using
pip install pgmpy
before running the code. This is just a basic example, and pgmpy offers many more functionalities for working with Bayesian networks, including parameter learning, structure learning, and more. You can refer to the pgmpy documentation for more information and advanced usage.
Bayesian Network in Machine Learning and Artificial Intelligence (AI)
Bayesian networks are fundamental in artificial intelligence and machine learning for representing and reasoning under uncertainty. They provide a graphical model to represent the probabilistic dependencies among a set of random variables compactly and intuitively.
Here’s how Bayesian networks are used in artificial intelligence:
- Probabilistic Reasoning: Bayesian networks enable reasoning under uncertainty by allowing us to calculate probabilities of events or states of variables given observed evidence. This is particularly useful in AI systems with inherent uncertainty, such as medical diagnosis, natural language understanding, and robotics.
- Decision Making: Bayesian networks can make decisions in uncertain environments. By incorporating probabilities and utility functions, Bayesian networks can help AI systems choose actions that maximize expected utility or minimize expected loss.
- Predictive Modeling: Bayesian networks can be employed for predictive modelling tasks, such as classification and regression. By learning the dependencies between variables from data, Bayesian networks can make predictions about unseen or future data points.
- Risk Assessment: Bayesian networks are widely used in risk assessment and risk analysis applications. They can model the uncertainty associated with various factors and events, allowing AI systems to assess and manage risks effectively.
- Diagnosis and Monitoring: In domains such as healthcare, Bayesian networks are used for medical diagnosis and patient monitoring. They can integrate diverse sources of information, including patient symptoms, test results, and medical history, to provide accurate diagnoses and monitor the progression of diseases.
- Anomaly Detection: Bayesian networks can be employed for anomaly detection in various applications, such as cybersecurity and predictive maintenance. By learning the expected behaviour of a system, Bayesian networks can identify deviations from the norm that may indicate anomalies or failures.
- Natural Language Processing (NLP): Bayesian networks are used in NLP tasks such as language modelling, part-of-speech tagging, and sentiment analysis. They can capture the probabilistic dependencies between words and linguistic features, improving the accuracy of NLP systems.
Conclusion
Bayesian networks offer a robust framework for representing and reasoning under uncertainty in various applications. Throughout this exploration, we’ve seen how Bayesian networks provide a principled way to model complex probabilistic relationships using graphical structures. By capturing dependencies among variables and quantifying uncertainty, Bayesian networks enable us to make informed decisions, perform inference tasks, and generate predictions in uncertain environments.
From the foundational concepts of probability theory to the intricacies of graphical models and inference algorithms, Bayesian networks offer a versatile toolkit for tackling real-world problems across various domains. Whether medical diagnosis, risk assessment, natural language processing, or autonomous systems, Bayesian networks provide a structured and intuitive approach to probabilistic modelling and reasoning.
Moreover, Bayesian networks continue to evolve with advancements in machine learning, artificial intelligence, and probabilistic inference techniques. Researchers and practitioners constantly explore new methods for understanding, inference, and uncertainty quantification in Bayesian networks, pushing the boundaries of what is possible in probabilistic modelling.
As we progress, Bayesian networks will remain a cornerstone in probabilistic reasoning, playing a crucial role in addressing the challenges of uncertainty and complexity in data-driven decision-making. With their ability to represent uncertainty explicitly, Bayesian networks empower us to make more informed, robust, and reliable decisions in the face of uncertainty, ultimately driving progress and innovation across various domains.












0 Comments