What is Self-Supervised Learning?
Self-supervised learning (SSL) is a machine learning technique where a model learns representations or features directly from the input data without explicit supervision or labelled targets. Unlike supervised learning, where models are trained on labelled data (input-output pairs) and unsupervised learning, which deals with unlabeled data, SSL utilizes the inherent structure or characteristics within the data to generate supervisory signals.
Table of Contents
In SSL, the model is trained to predict certain parts of the input data from other parts. This is achieved by creating pretext tasks, where the model is given a task that doesn’t require external labelling but still contains valuable information. By solving these tasks, the model learns meaningful representations that can be used for downstream tasks like classification, regression, or clustering.
For instance, in computer vision, SSL might involve training a model to predict the rotation or orientation of an image patch given other patches from the same image. While in natural language processing this could entail predicting missing words in a sentence based on the context of the surrounding words.

The continuous bag-of-words and skip-gram models are examples of self-supervised learning algorithms.
The core idea is that by leveraging the inherent structure or information within the data, the model can learn meaningful and transferable representations, reducing the need for large amounts of labelled data and potentially improving generalization to new, unseen data. SSL has shown promise across various domains, including image recognition, natural language understanding, and reinforcement learning.
Understanding Self-Supervised Learning
Self-supervised learning (SSL) is an innovative approach within machine learning, redefining how models acquire knowledge without explicit human-labeled data. At its core, SSL thrives on tapping into inherent structures and patterns within the data itself, circumventing the traditional need for labelled examples to guide learning.
Distinguishing SSL from Traditional Learning Paradigms
Distinguishing Self-Supervised Learning (SSL) from traditional learning paradigms like supervised and unsupervised learning illuminates its unique position in the machine learning landscape.
While supervised learning relies on meticulously labelled data pairs for training and unsupervised learning delves into unlabeled data to unveil inherent patterns, SSL represents a middle ground.
Unlike supervised learning, which heavily leans on labelled datasets, SSL bypasses the need for extensive external annotations by formulating auxiliary tasks derived from the data. This approach enables SSL to bridge the gap between supervised and unsupervised learning, harnessing the intrinsic structure of the data to create self-generated tasks that guide model learning.
Core Principles and Methodologies of SSL
Self-supervised learning (SSL) operates on foundational principles and methodologies that redefine how models glean meaningful insights directly from data without explicit supervision or labelled targets. These methodologies form the backbone of SSL’s approach:
- Pretext Tasks: At the heart of SSL lies the creation of pretext tasks. These tasks are carefully designed to present the model with challenges derived from the data’s inherent structure. These challenges don’t require external annotations but serve as guiding signals for the model’s learning process.
- Feature Extraction and Representation Learning: SSL focuses on extracting high-quality features and learning representations from raw data. By deciphering intricate patterns within the data, the model creates drawings that encapsulate essential characteristics, enhancing its ability to understand and generalize across various tasks.
- Leveraging Context and Predictive Learning: SSL leverages contextual information to facilitate predictive learning. This involves training the model to predict missing or obscured parts of the data based on the information available within the dataset. By anticipating these elements, the model learns to capture nuanced relationships and dependencies within the data.
SSL’s core principles, centred on pretext tasks, feature extraction, and predictive learning, collectively equip models to derive valuable insights from the data landscape autonomously, revolutionizing the learning process and paving the way for enhanced model adaptability and generalization. Leveraging these tasks, SSL empowers models to glean richer, more generalized representations directly from the data, thereby reducing the dependency on exhaustive external labelling efforts while surpassing the generality of unsupervised techniques.
What are Some Examples of Pretext Tasks?
Pretext tasks are integral in Self-Supervised Learning (SSL) as they form the basis for the model to learn meaningful representations from unlabeled data. Here are a few examples of pretext tasks used in SSL:
- Image Inpainting: Given an image with a portion deliberately masked or removed, the model is tasked with predicting or filling in the missing part based on the context of the surrounding image. This encourages the model to learn about spatial relationships and contextual understanding within images.
- Rotation Prediction: An image is randomly rotated, and the model is trained to predict the degree or angle of rotation applied to the image. By doing so, the model learns invariant representations of objects, irrespective of their orientations, fostering robust feature learning.
- Masked Language Modeling: In natural language processing, a sentence is partially masked by replacing certain words with placeholders, and the model is tasked with predicting the missing or masked words based on the context provided by the rest of the sentence. This encourages the model to understand language context and semantics.
- Temporal Order Prediction: The model might be trained to predict the correct temporal order of shuffled sequences or frames in sequential data like videos or time-series. By reconstructing the original sequence, the model learns temporal dependencies and patterns.
- Colourization: Given a grayscale image, the model is tasked with predicting the image’s original colours. This pretext task encourages the model to understand the semantic meaning and relationships between different image parts.
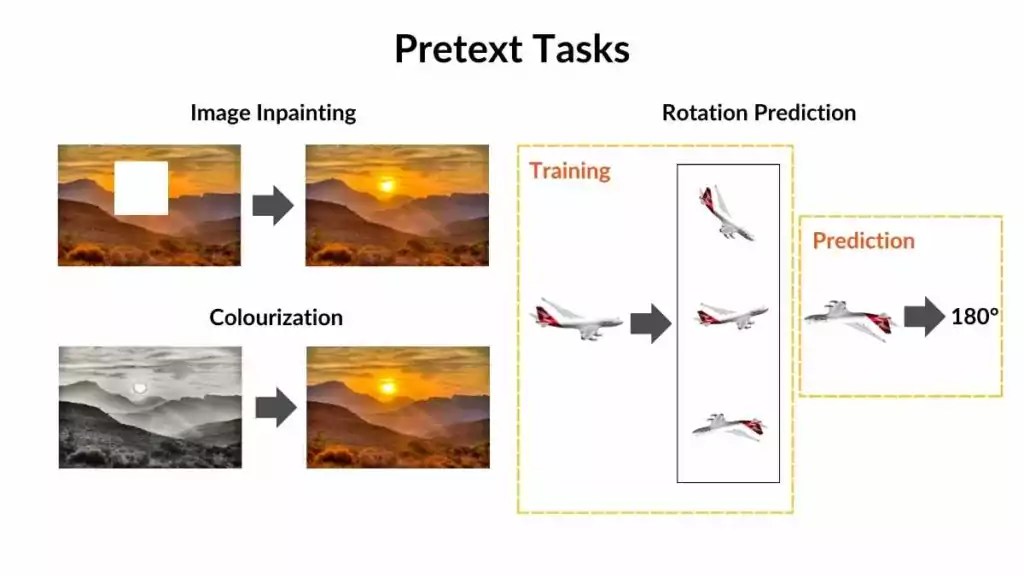
These pretext tasks serve as guiding signals for SSL models to extract meaningful representations from the data. They’re carefully designed to capture various aspects of the data’s structure and semantics, enabling the model to learn rich and transferable features without explicit supervision.
Benefits of Self-Supervised Learning
Self-supervised learning (SSL) introduces a paradigm shift in machine learning, offering a range of advantages that redefine how models learn from data without explicit supervision. The benefits of SSL encompass various aspects:
1. Addressing Data Scarcity and Labeled Data Challenges
- Mitigating the Need for Extensive Labeled Data: SSL reduces dependence on large, annotated datasets, making it feasible to train models even when labelled data is scarce or costly.
- Leveraging Unlabeled Data: SSL efficiently utilizes vast pools of unlabeled data, tapping into their latent information to generate valuable supervisory signals for training.
2. Improving Model Generalization and Performance
- Learning Richer Representations: SSL facilitates the extraction of high-quality, nuanced representations directly from raw data, enhancing a model’s ability to generalize across diverse tasks and datasets.
- Enhanced Transfer Learning: Models trained using SSL often exhibit superior transfer learning capabilities, as the learned representations are more adaptable and applicable to new, unseen domains or tasks.
3. Reducing Human Intervention and Labor-Intensive Labeling Processes
- Cost and Time Efficiency: By minimizing the need for manual labelling efforts, SSL streamlines the training process, reducing time and monetary investments associated with data annotation.
- Automation and Scalability: SSL’s reliance on self-generated tasks enables automated learning processes, facilitating scalability across domains without significant human intervention.
The manifold benefits of SSL underscore its significance in revolutionizing machine learning methodologies. By harnessing intrinsic data characteristics and minimizing reliance on labelled data, SSL improves model performance and adaptability and addresses critical challenges related to data scarcity and annotation efforts, ultimately paving the way for more efficient and scalable learning systems.
Techniques and Approaches in Self-Supervised Learning
Self-supervised learning (SSL) encompasses a spectrum of innovative techniques and methodologies designed to enable models to learn representations from raw data without explicit supervision. These approaches redefine how models acquire knowledge and include several prominent methods:
Contrastive Learning
- SimCLR (SimCLRv1 and SimCLRv2): Utilizes contrastive learning by training models to maximize agreement between differently augmented views of the same data and minimize agreement between different data instances.
- SimSiam: A simplified variant of contrastive learning, SimSiam maximizes agreement between differently transformed views of the same input without using negative examples.
Generative Modeling
- Autoencoders: Leveraging encoder-decoder architectures, autoencoders learn to reconstruct input data, effectively capturing essential features during encoding.
- Generative Adversarial Networks (GANs): GANs learn to generate data that mimics the training data distribution. SSL applications focus on utilizing the known representations in the generator or discriminator for downstream tasks.

GANs can create realist art because they have been trained using self-supervised learning.
Predictive Learning
- Pretext Tasks: Creating pretext tasks where the model predicts certain parts of the input data from other parts, such as predicting missing patches in images, masked words in text, or temporal order of sequences.
- Temporal Contrastive Learning: Involves predicting the relative order or temporal relationship between data sequences, fostering models’ understanding of temporal dependencies.
These techniques showcase the diversity and versatility of SSL methodologies, each geared towards enabling models to extract meaningful representations from data without explicit supervision.
Self-Supervised Learning in Different Domains
Self-supervised learning (SSL) exhibits remarkable adaptability across various domains, revolutionizing learning paradigms by extracting valuable insights from data without explicit supervision. Its applications span diverse fields, showcasing its effectiveness in:
Natural Language Processing (NLP)
- Masked Language Modeling: SSL tasks involve predicting missing or masked words within a sentence, as seen in models like BERT (Bidirectional Encoder Representations from Transformers) and its variants.
- Next Sentence Prediction: Models are trained to predict whether a given sentence logically follows another, enhancing understanding of contextual relationships.
Computer Vision (CV)
- Image Inpainting: SSL methods predict missing parts or fill in regions of an image to reconstruct the complete picture, aiding in understanding context and spatial relationships within images.
- Rotation Prediction: Models learn to predict the degree of rotation applied to an image, fostering robust feature learning and spatial understanding.
Reinforcement Learning (RL)
- Self-Generated Exploration: SSL empowers RL agents to create their learning tasks, guiding exploration in complex environments without explicit external rewards.
- State Representation Learning: Models learn representations from raw sensory inputs, improving generalization and adaptability in RL tasks.
SSL’s versatility shines through its applications in NLP, CV, and RL domains, demonstrating its ability to autonomously learn rich representations and contextual understanding from raw data. By leveraging SSL techniques tailored to specific domains, models acquire nuanced knowledge, fostering improved performance and adaptability in diverse real-world scenarios.
Challenges and Limitations of Self-Supervised Learning
While Self-Supervised Learning (SSL) presents a transformative approach to learning from unlabeled data, it grapples with several challenges and limitations that shape its application and effectiveness:
Evaluation Metrics and Benchmarks
- Lack of Standardized Evaluation: Evaluating SSL methods remains challenging due to the absence of universally accepted benchmarks and metrics that accurately capture the quality of learned representations.
- Subjectivity in Evaluation: Assessing the quality of learned representations often involves subjective judgments, leading to variability in evaluation results across different studies.
Transfer Learning Issues
- Domain-Specific Representations: SSL models might struggle to generalize well across diverse domains, leading to issues when transferring learned representations to unrelated tasks or datasets.
- Limited Transferability: Representations learned through SSL might not transfer optimally to tasks drastically different from the pretext tasks used during training.
Ethical Considerations and Biases
- Amplification of Biases: SSL models, if not carefully designed and trained, can perpetuate biases in the training data, leading to ethical concerns and reinforcing societal prejudices.
- Transparency and Interpretability: Complex SSL models might lack clarity, making it challenging to interpret how and why certain representations are learned, posing challenges to trust and interpretability.
Navigating these challenges and limitations is crucial for advancing the efficacy and applicability of SSL. Addressing issues related to evaluation methodologies, transferability of learned representations, and ethical implications is pivotal in fostering more robust, fair, and transparent SSL frameworks.
Tools, Libraries, and Resources for Self-Supervised Learning
The burgeoning interest in Self-Supervised Learning (SSL) has spurred the development of various tools, libraries, and resources tailored to support those delving into SSL methodologies. These resources encompass:
Frameworks and Libraries
- PyTorch: Offers dedicated modules and libraries like torchvision, providing implementations of SSL methods such as SimCLR, MoCo, and others.
- TensorFlow: Provides TensorFlow Hub and TensorFlow Addons with modules for SSL tasks, facilitating easy experimentation and implementation of SSL models.
- JAX: Growing in popularity for its flexibility and efficiency, JAX offers libraries enabling SSL implementation and experimentation.
Pre-trained Models and Datasets
- ImageNet: Though primarily used for supervised learning, SSL subsets of ImageNet are utilized for pretext tasks, providing a rich source for pre-training SSL models.
- Hugging Face’s Transformers: Offers pre-trained language models such as BERT, RoBERTa, and GPT-3, which can be fine-tuned using SSL techniques for downstream tasks.
Future Trends and Applications of Self-Supervised Learning
Self-supervised learning (SSL) continues to evolve and pave the way for groundbreaking advancements in machine learning. Several emerging trends and potential applications point towards the future trajectory of SSL:
Hybrid SSL Approaches
- Fusion with Supervised Learning: Integration of SSL techniques with supervised learning methods for improved generalization and robustness across diverse tasks.
- Semi-Supervised Learning: Combining SSL with a small amount of labelled data to enhance model performance, addressing scenarios with limited annotated datasets.
Multimodal Learning
- Fusion of Vision and Language: Advancements in learning joint representations from visual and textual data through SSL, facilitating models’ comprehension of multimodal inputs.
- Audio-Visual Learning: Expanding SSL techniques to learn representations from audio and visual data enables models to understand richer sensory information.
Self-Supervised Reinforcement Learning:
- Autonomous Task Formulation: Further development of SSL techniques enables RL agents to generate tasks, guiding exploration and learning in complex environments.
- Hierarchical Reinforcement Learning: Leveraging SSL to learn hierarchical representations, enhancing RL agents’ ability to solve tasks at multiple levels of abstraction.
Continual and Lifelong Learning
- Lifelong SSL: Evolution of SSL models capable of continual learning from streaming data, adapting and updating representations over time.
- Catastrophic Forgetting Mitigation: Strategies to prevent forgetting previously learned representations while continuously learning new information using SSL techniques.
Ethical and Fair Learning
- Bias Mitigation: Innovations in SSL models to address biases and fairness issues, ensuring equitable and unbiased representations.
- Interpretability and Explainability: Advancements to enhance the interpretability of SSL models, enabling better understanding and control of learned representations.
The future of SSL holds promise in reshaping various facets of machine learning, spanning from multimodal learning to continual adaptation and ethical considerations. SSL is poised to propel AI systems towards greater adaptability, understanding, and fairness by exploring these trends and applications, catalyzing transformative changes across diverse domains.
Key Takeaways
- Self-supervised learning (SSL) revolutionizes machine learning by enabling models to learn from unlabeled data through self-generated tasks, reducing dependency on annotated datasets.
- SSL relies on pretext tasks, extracting valuable representations from raw data and enhancing model generalization and adaptability across various domains.
- Its applications span NLP, CV, and RL, showcasing its effectiveness in tasks like masked language modelling, image inpainting, and autonomous task generation in reinforcement learning.
- Challenges in SSL include evaluation metrics, transferability issues, and ethical considerations, necessitating efforts for standardized benchmarks, improved transfer learning, and bias mitigation.
- SSL resources like frameworks and pre-trained models empower you to explore and innovate in SSL methodologies.
- Future trends envision hybrid SSL approaches, multimodal learning, SSL in reinforcement learning, continual learning, and a focus on ethical, fair, and interpretable models.
- The evolution of SSL holds the potential to redefine AI systems, fostering adaptability, fairness, and continual learning, shaping the future landscape of machine learning.












0 Comments