What is sequence-to-sequence?
Sequence-to-sequence (Seq2Seq) is a deep learning architecture used in natural language processing (NLP) and other sequence modelling tasks. It is designed to handle input sequences of variable length and generate output sequences of varying length, making it suitable for tasks like machine translation, text summarization, speech recognition, and more.
Table of Contents
To appreciate Seq2Seq models, let’s begin by acknowledging the ubiquity of sequences in our world. Sequences are everywhere, from natural language sentences and speech signals to financial time series and genomic data. A sequence is simply an ordered list of elements and the order matters. Understanding, predicting, and generating sequences pose unique challenges compared to traditional fixed-size data.
Traditional machine learning models, like feedforward neural networks, are unsuited for handling sequences because they expect inputs and outputs of fixed dimensions. Seq2Seq models, on the other hand, are specifically designed to tackle variable-length sequences. This flexibility allows Seq2Seq models to excel in many tasks with pivotal sequences.
The Encoder-Decoder Architecture
At the heart of Seq2Seq models lies the encoder-decoder architecture. This architectural paradigm mirrors the human thought process: first, we gather information, and then we use that information to generate a response or make a decision.
- Encoder: The encoder comprehends the input sequence and captures its essential information. It processes the sequence step by step, often using recurrent neural networks (RNNs), long short-term memory networks (LSTMs), or, more recently, transformer-based architectures. As it does so, it accumulates knowledge in a fixed-size context vector, sometimes called the “thought” vector.
- Decoder: The decoder takes over once the input sequence is encoded into a context vector. It generates the output sequence based on the information stored in the context vector. Like the encoder, the decoder can also employ RNNs, LSTMs, transformers, or other sequential modelling techniques to produce the output sequence. This generation process is typically performed one step at a time, with each step considering the previous output and the context vector.
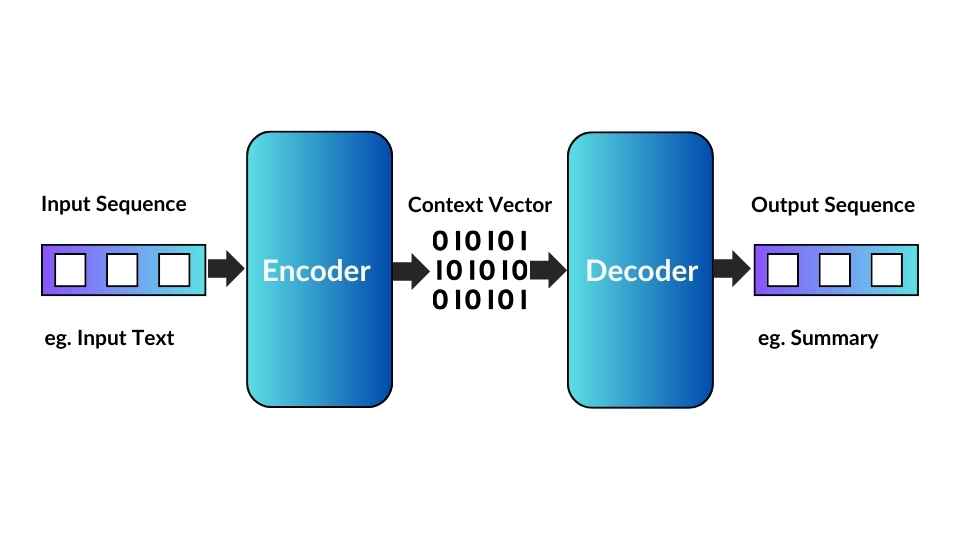
Sequence-to-sequence architecture
What are sequence-to-sequence models used for?
Seq2Seq models are exceptionally versatile. They can be applied to various problems involving sequences, making them indispensable in natural language processing, speech recognition, and more. For instance:
- Machine Translation: Seq2Seq models have revolutionized machine translation by enabling systems to translate text from one language to another, capturing language structure and context nuances.
- Text Summarization: They are adept at summarizing lengthy texts into concise and coherent summaries, a valuable skill in information retrieval and content extraction.
- Speech Recognition: Seq2Seq models can convert spoken language into written text, driving the development of voice assistants and transcription services.
In the following sections, we’ll dive deeper into the inner workings of Seq2Seq models, explore the building blocks that make them tick, and demonstrate how to build your own Seq2Seq model for various applications. By the end of this blog post, you’ll have a solid grasp of Seq2Seq models and the tools to leverage their power in your projects.
The Encoder-Decoder Architecture
In the previous section, we introduced the concept of sequence-to-sequence (Seq2Seq) models and their importance in handling data sequences. Now, let’s dive deeper into the fundamental architecture of Seq2Seq models, known as the encoder-decoder framework. Understanding how these components work together is essential for harnessing the full potential of Seq2Seq models.
The Encoder: Capturing Context
The encoder is the first half of the Seq2Seq model, responsible for processing the input sequence and summarizing its essential information into a fixed-size context vector. This context vector is a “thought” vector, encapsulating the knowledge extracted from the input sequence. Here’s how the encoder typically functions:
- Embedding Layer: The input sequence, often consisting of discrete elements like words or tokens, is passed through an embedding layer. This layer converts each element into a continuous vector representation, making it suitable for neural network processing.
- Recurrent Layers (or Transformers): Following the embedding layer, recurrent layers, such as RNNs or LSTMs, process the embedded input sequence step by step. Modern Seq2Seq models may use transformer-based encoders for parallelism and improved performance.
- Context Vector: As the encoder processes the input sequence, it accumulates information as hidden states. Once the input sequence is processed, the final hidden state is used as the context vector. This context vector encapsulates the essence of the input sequence and serves as the starting point for the decoder.
The Decoder: Generating Output Sequences
The decoder, the second half of the Seq2Seq model, takes the context vector produced by the encoder and generates the output sequence. Its primary role is to produce a sequence of elements based on the context vector and, optionally, some initial input. Here’s how the decoder typically operates:
- Embedding Layer: Similar to the encoder, the decoder’s first step is to use an embedding layer to transform the input sequence (or individual elements) into continuous vector representations.
- Recurrent Layers (or Transformers): Like the encoder, the decoder can employ recurrent layers or transformers to process the embedded input. These layers generate output sequences one step at a time, considering both the context vector and the previously generated elements of the output sequence.
- Output Layer: The decoder produces a probability distribution over the possible output elements at each step. This distribution is then used to sample the next component in the output sequence. The output layer is typically a softmax layer that converts the model’s predictions into probabilities.
- Teacher Forcing (Optional): “Teacher forcing” is often used during training. It involves feeding the true target sequence elements as inputs to the decoder rather than using its predictions. This helps stabilize training but may lead to a discrepancy between training and inference.
Cooperation of Encoder and Decoder
The synergy between the encoder and decoder enables Seq2Seq models to shine in various tasks. The encoder summarizes the input sequence into a context vector, which serves as a compact representation of the input’s information. The decoder then uses this context vector to generate the output sequence, one step at a time.
The encoder-decoder architecture is a powerful paradigm for handling sequences of varying lengths. However, it’s not without challenges. Seq2Seq models must learn to capture relevant information in the context vector and effectively decode it into the output sequence. To address these challenges, techniques like attention mechanisms, which allow the model to focus on specific parts of the input sequence, have been introduced and have greatly improved the capabilities of Seq2Seq models.
The following section will explore the building blocks that makeup Seq2Seq models, including embeddings, recurrent layers, and attention mechanisms. These components are the key to unlocking the full potential of Seq2Seq models in various applications.
Building Blocks of Sequence-to-Sequence Models
In the previous section, we explored the fundamental architecture of sequence-to-sequence (Seq2Seq) models, emphasizing the crucial roles played by the encoder and decoder. Now, let’s look at the building blocks that constitute Seq2Seq models and enable them to excel in various sequence-related tasks.
The Role of Embeddings
One essential building block in Seq2Seq models is embeddings. Embeddings are vector representations of discrete elements such as words or tokens. They serve as the bridge between the discrete world of sequences and the continuous space of neural networks. Here’s how embeddings work in Seq2Seq models:
- Input Embeddings: At the beginning of the encoder and decoder, each element of the input and target sequences is embedded into continuous vectors. These embeddings capture semantic information about the elements, allowing the model to work with them in a continuous space. Training the embeddings is part of the model’s learning process, which means they adapt to the task.
- Shared Embeddings: In many Seq2Seq models, the same embedding layer is used for input and target sequences. This shared embedding space enables the model to represent input and output elements, facilitating better learning consistently.
Recurrent Layers vs. Transformers
Seq2Seq models require layers that can handle sequences, and two popular choices are recurrent layers (RNNs and LSTMs) and transformer-based architectures. Here’s a brief comparison:
- Recurrent Layers (RNNs and LSTMs): These layers process sequences sequentially, one element at a time. They maintain hidden states that capture information from previous steps, allowing them to capture sequential dependencies effectively. However, they may struggle with long sequences and can be computationally intensive.
- Transformers: Transformers, introduced in the famous “Attention Is All You Need” paper, have revolutionized Seq2Seq models. They use self-attention mechanisms to capture dependencies between all elements in a sequence in parallel. This parallelism makes transformers highly efficient and suitable for long sequences. They have become the go-to choice for many Seq2Seq applications.
The Power of Attention Mechanisms
Attention mechanisms are a game-changer in Seq2Seq modelling. They allow the model to selectively focus on specific parts of the input sequence when generating the output sequence. The attention mechanism consists of three main components:
- Query: The decoder generates the element at a given time step.
- Key-Value Pairs: Elements of the input sequence, serving as keys and values.
- Attention Scores: Calculated based on the compatibility between the query and the keys.
The attention scores determine how much attention the model should pay to each input sequence element when generating the current output element. This dynamic attention mechanism enables Seq2Seq models to handle long-range dependencies and accurately align input elements with output elements.
What are some variations of sequence-to-sequence models?
Seq2Seq models are highly adaptable and have seen numerous variations and enhancements. Here are some notable techniques and variations:
- Teacher Forcing: During training, Seq2Seq models can use the true target sequence as inputs to the decoder instead of using its predictions. This technique, known as “teacher forcing,” helps stabilize training but can lead to discrepancies between training and inference.
- Beam Search: Beam search is often employed for generating sequences during inference. It explores multiple potential output sequences in parallel and selects the one with the highest probability. This technique often leads to more coherent and accurate outputs.
In the upcoming sections, we’ll explore real-world applications of Seq2Seq models, including machine translation, text summarization, and more. Additionally, we’ll provide practical examples and demonstrate how to build Seq2Seq models for specific tasks using popular deep learning frameworks.
What are common applications of sequence-to-sequence models?
Now that we’ve explored the foundational components of sequence-to-sequence (Seq2Seq) models, it’s time to delve into the exciting real-world applications, where these models have significantly impacted. Seq2Seq models have proven their versatility by addressing various sequence-related tasks, offering state-of-the-art solutions across multiple domains.
1. Machine Translation Machine translation, the task of automatically translating text from one language to another, has been revolutionized by Seq2Seq models. Here’s how Seq2Seq models excel in this application:
- Bidirectional Understanding: Seq2Seq models can encode input sentences in the source language and generate equivalent sentences in the target language. This bidirectional understanding allows them to capture language structure and context nuances.
- Transformer-Based Models: Transformer-based Seq2Seq models, such as the famous “Transformer” architecture, have become the backbone of modern machine translation systems. They use self-attention mechanisms to handle long-range dependencies effectively.
- Multilingual Translation: Seq2Seq models can handle multiple languages, enabling the development of multilingual translation systems that can translate between numerous language pairs.
2. Text Summarization
Seq2Seq models have also made significant strides in abstractive text summarization. Abstractive summarization involves generating a concise and coherent summary of a longer text instead of extractive summarization, which selects and combines existing sentences. Here’s how Seq2Seq models shine in this task:
- Content Understanding: Seq2Seq models effectively understand the content of the input text and generate summaries that capture the critical information, making them highly suitable for news summarization, document summarization, and content extraction.
- Advanced Architectures: Variations of Seq2Seq models, often incorporating attention mechanisms and transformer-based architectures, have improved the quality and coherence of generated summaries.
3. Speech Recognition
Seq2Seq models play a pivotal role in converting spoken language into written text, a task known as automatic speech recognition (ASR). Here’s why Seq2Seq models are instrumental in this application:
- Audio Processing: ASR involves processing audio waveforms as input sequences, and Seq2Seq models, particularly those with attention mechanisms, excel in capturing spoken language patterns.
- Accuracy Improvement: Using Seq2Seq models has led to significant improvements in ASR accuracy, making them essential for voice assistants, transcription services, and more.
- Multilingual ASR: Seq2Seq models can also be adapted for multilingual ASR, where they accurately transcribe speech in multiple languages.
4. Image Captioning
Seq2Seq models are not limited to processing text data; they can also handle image data effectively. In image captioning, Seq2Seq models generate natural language descriptions of images. Here’s why Seq2Seq models are a natural fit for this task:
- Multimodal Understanding: Seq2Seq models combine image features extracted by convolutional neural networks (CNNs) with textual generation capabilities, enabling them to describe images in a human-readable format.
- Creative Descriptions: Seq2Seq models can generate creative and contextually relevant image captions, which is valuable in applications like content generation and accessibility for the visually impaired.
- Visual question Answering: Seq2Seq models are used in tasks like visible question answering (VQA), where they generate answers to questions about images, demonstrating their versatility in multimodal applications.
These are just a few examples of the many applications where Seq2Seq models have proven their worth. From machine translation to summarization, speech recognition, and image captioning, Seq2Seq models continue to drive innovation and advance the capabilities of machine learning in handling sequential data.
In the next section, we’ll take a more hands-on approach and guide you through building your own Seq2Seq model for a specific task using popular deep learning frameworks.
How to build your sequence-to-sequence model
Now that we’ve explored the fundamental concepts and applications of sequence-to-sequence (Seq2Seq) models, it’s time to get hands-on and guide you through building your own Seq2Seq model. Whether you’re interested in machine translation, text summarization, or another sequence-related task, this section will provide the essential steps to get started.
Step 1: Data Preparation
The first crucial step is data preparation. You’ll need a dataset that suits your task. You’ll need parallel text data in both source and target languages for machine translation. You’ll require a corpus of text documents and their corresponding summaries for text summarization. You might need to tokenize and preprocess the data depending on your task.
Step 2: Define Your Model Architecture
The choice of model architecture depends on your task and data. You can create a Seq2Seq model using popular deep learning frameworks like TensorFlow or PyTorch. Here’s a high-level overview of the steps involved:
- Encoder: Define the encoder component to process the input sequence and generate a context vector. You can choose from various architectures, including LSTM, GRU, or transformer-based encoders.
- Decoder: Create the decoder component responsible for generating the output sequence based on the context vector and, optionally, some initial input. You can choose from different recurrent layers or transformer-based architectures like the encoder.
- Embeddings: Implement embeddings for the input and output sequences. These embeddings allow the model to work with discrete elements, such as words or tokens, in a continuous vector space.
- Attention Mechanisms (Optional): Depending on your task and model architecture, you might want to incorporate attention mechanisms to improve the model’s ability to focus on relevant parts of the input sequence.
- Loss Function and Optimization: Define an appropriate loss function for your task, such as categorical cross-entropy for text generation tasks. Choose an optimization algorithm like Adam or SGD to train your model.
Step 3: Training and Evaluation
Once your model architecture is defined, it’s time to train and evaluate the model:
- Training: Use your prepared dataset to train the model. During training, you’ll input source sequences and their corresponding target sequences and update the model’s parameters to minimize the chosen loss function. Consider techniques like teacher forcing to improve training stability.
- Validation: Monitor the model’s performance on a validation dataset to prevent overfitting. Adjust hyperparameters and model architecture as needed.
- Testing: Evaluate the model on a separate test dataset to assess its generalization to unseen data.
Step 4: Inference
After training, you can use your Seq2Seq model for inference on new data:
- Inference Pipeline: Set up an inference pipeline that takes input sequences, preprocesses them (e.g., tokenization), passes them through the encoder, and generates the output sequences using the decoder.
- Beam Search (Optional): For tasks like text generation, consider using beam search during inference to improve the quality of generated sequences.
Step 5: Fine-Tuning and Iteration
Seq2Seq model building is an iterative process. You may need to fine-tune your model’s hyperparameters, adjust the architecture, or experiment with different techniques to improve performance on your task.
Step 6: Deployment (Optional)
If your Seq2Seq model is intended for production use, consider deploying it as a service or integrating it into your application. Frameworks like TensorFlow Serving and Flask can help you deploy models in a production environment.
Step 7: Experiment and Explore
Don’t be afraid to experiment and explore! Seq2Seq models offer a wide range of possibilities, and you can adapt them to various tasks beyond the ones mentioned in this blog post. Consider tackling challenges like code generation, conversational agents, or creative content generation.
Remember that building Seq2Seq models requires a combination of domain expertise, data preparation, and experimentation. It’s a rewarding journey that allows you to leverage the power of deep learning for sequence-related tasks.
How to implement sequence-to-sequence models in PyTorch
In PyTorch, you can implement a sequence-to-sequence (Seq2Seq) model for various tasks such as machine translation, text summarization, and speech recognition. Here, we will provide a high-level overview of how to build a Seq2Seq model using PyTorch. Note that this is a simplified example, and actual implementations can vary depending on the specific task and model architecture.
Assuming you have PyTorch installed, you can create a basic Seq2Seq model as follows:
import torch
import torch.nn as nn
import torch.optim as optim
# Define the Encoder
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell
# Define the Decoder
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden, cell
# Define the Seq2Seq model
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
# src: source sequence, trg: target sequence
trg_len = trg.shape[0]
batch_size = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# Initialize the hidden and cell states of the encoder
hidden, cell = self.encoder(src)
# Take the <sos> token as the first input to the decoder
input = trg[0,:]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputsThis is the basic outline of a Seq2Seq model with an encoder and decoder. It would help if you defined the input and output dimensions, embedding dimensions, hidden dimensions, and other hyperparameters based on your specific task and dataset.
You’ll also need to define the training loop, loss function, and optimization method suitable for your task and data. Additionally, you may want to incorporate techniques like attention mechanisms for better Seq2Seq performance in more complex tasks.
How to implement sequence-to-sequence in Tensorflow
Creating a sequence-to-sequence (Seq2Seq) model using TensorFlow involves defining an encoder-decoder architecture. Here, I’ll provide a simplified example using TensorFlow. Remember that real-world implementations can vary significantly based on the specific task and model architecture.
Assuming you have TensorFlow installed, here’s an outline of how to build a Seq2Seq model using TensorFlow:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.models import Model
# Define the Encoder
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.embedding = Embedding(vocab_size, embedding_dim)
self.lstm = LSTM(enc_units, return_sequences=True, return_state=True)
def call(self, x):
x = self.embedding(x)
output, state_h, state_c = self.lstm(x)
return output, state_h, state_c
# Define the Decoder
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.embedding = Embedding(vocab_size, embedding_dim)
self.lstm = LSTM(dec_units, return_sequences=True, return_state=True)
self.dense = Dense(vocab_size, activation='softmax')
def call(self, x, initial_state):
x = self.embedding(x)
output, _, _ = self.lstm(x, initial_state=initial_state)
prediction = self.dense(output)
return prediction
# Define the Seq2Seq Model
class Seq2SeqModel(tf.keras.Model):
def __init__(self, encoder, decoder):
super(Seq2SeqModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
def call(self, inputs):
source, target = inputs
enc_output, enc_state_h, enc_state_c = self.encoder(source)
dec_output = self.decoder(target, initial_state=[enc_state_h, enc_state_c])
return dec_output
# Define the hyperparameters and instantiate the model
vocab_size = 10000 # Example vocabulary size
embedding_dim = 256
enc_units = 512
dec_units = 512
encoder = Encoder(vocab_size, embedding_dim, enc_units)
decoder = Decoder(vocab_size, embedding_dim, dec_units)
seq2seq_model = Seq2SeqModel(encoder, decoder)
# Compile the model (you may choose an appropriate optimizer and loss function)
seq2seq_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])In this example, we define an encoder-decoder architecture using LSTM layers. You must adapt this code to your specific task, prepare data, and define training and evaluation loops. Additionally, consider adding mechanisms like attention to improve performance for more complex tasks.
Challenges and Future Directions
As we near the end of our journey through the world of sequence-to-sequence (Seq2Seq) models, it’s essential to acknowledge the challenges these models face and consider their exciting directions. Seq2Seq models have made remarkable strides, but there’s still room for improvement and innovation.
What are the challenges in sequence-to-sequence modelling?
- Handling Long Sequences: Seq2Seq models can struggle with long sequences because they rely on recurrent layers or self-attention mechanisms. Addressing this challenge is a crucial area of ongoing research.
- Training Instability: Training Seq2Seq models can sometimes be unstable, leading to issues like vanishing gradients or mode collapse. Techniques like gradient clipping and curriculum learning are employed to mitigate these problems.
- Inference Speed: While transformer-based Seq2Seq models are highly effective, they can be computationally intensive during inference, particularly for real-time applications. Optimizing model inference speed is a priority.
- Multimodal Seq2Seq: Extending Seq2Seq models to handle multiple modalities (e.g., text and images) remains a challenging research area, with applications in areas like visual question answering (VQA) and more.
What does the future hold for sequence-to-sequence modelling?
- Advanced Architectures: Seq2Seq models will continue to benefit from advances in architecture design. Researchers are exploring novel model architectures and ways to make them more efficient and capable.
- Few-Shot and Zero-Shot Learning: Seq2Seq models are being extended to tackle few-shot and zero-shot learning scenarios, where the model can generalize from minimal examples or adapt to entirely new tasks.
- Multilingual and Cross-Lingual Models: Developing multilingual and cross-lingual Seq2Seq models is ongoing, enabling seamless translation and understanding across multiple languages.
- Continual Learning: Seq2Seq models that can continuously adapt and learn from new data are promising, particularly for applications that require lifelong learning.
- Interpretable Seq2Seq: Researchers are making Seq2Seq models more interpretable, allowing users to understand why the model makes specific predictions or generates particular sequences.
- Ethical Considerations: As Seq2Seq models become more capable, ethical considerations around their use and potential biases in the data they learn from are increasingly important. Research in this area will continue to evolve.
- Integration with Real-World Systems: Seq2Seq models will become more tightly integrated into real-world systems and applications, impacting fields such as healthcare, finance, and education.
Conclusion
In deep learning, where the power to model and understand sequential data is paramount, sequence-to-sequence (Seq2Seq) models have emerged as a transformative force. Throughout this blog post, we’ve embarked on a journey into the heart of Seq2Seq models, exploring their architecture, applications, and the road ahead.
At their core, Seq2Seq models encapsulate the essence of sequential data processing. The encoder’s role is to comprehend the input sequence, capturing its critical information, while the decoder generates meaningful output sequences, leveraging the knowledge encoded in the context vector. This elegant architecture has unlocked a world of possibilities in various domains.
We’ve witnessed Seq2Seq models thriving in real-world applications. From breaking down language barriers through machine translation to distilling the essence of lengthy texts in text summarization, these models have rewritten the rules of engagement. They’ve paved the way for accurate speech recognition systems, given voice-to-image descriptions in image captioning, and offered answers to questions posed to visual content in visual question answering (VQA).
But the journey doesn’t end here; it merely begins. Seq2Seq models face challenges, from handling long sequences to training stability, and addressing these challenges is an ongoing mission. As researchers and developers push the boundaries, we anticipate exciting developments.
In the future, advanced architectures will take centre stage, ushering in a new era of efficiency and capability. Few-shot and zero-shot learning will make Seq2Seq models more adaptive, and they will converse fluently in multiple languages and across modalities. Continual learning will imbue them with the wisdom of experience, and ethical considerations will shape their deployment.
As Seq2Seq models become increasingly integrated into real-world systems, their impact will reverberate across industries, transforming healthcare, finance, education, and beyond.
Whether you’re a practitioner harnessing Seq2Seq models for practical applications or a researcher exploring the forefront of deep learning, you are contributing to a dynamic field that has the potential to redefine how we understand and work with sequences. The power of Seq2Seq models is not confined to a single domain but extends to every corner of sequential data, unlocking insights, enabling communication, and shaping the future.












0 Comments