Outlier detection in machine learning Outlier detection is a task in machine learning and data analysis involving identifying points that deviate significantly from the rest of the data. These data...

Outlier detection in machine learning Outlier detection is a task in machine learning and data analysis involving identifying points that deviate significantly from the rest of the data. These data...
![Zero-shot Classification [Top 6 Models, How To Tutorial In Python & Alternatives]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/08/zero-shot-classification.jpg?fit=1200%2C675&ssl=1)
What is zero-shot classification? Zero-shot classification is a machine learning approach in which a model can classify data into multiple classes without any specific training examples for those...
![How To Apply Feature Scaling In Machine Learning [Top Methods & Tutorials In Python]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/07/min-max-feature-scaling.jpg?fit=1200%2C675&ssl=1)
What is feature scaling in machine learning? Feature scaling is a preprocessing technique used in machine learning and data analysis to bring all the input features to a similar scale. It is...

What is k-fold cross-validation? K-fold cross-validation is a popular technique used to evaluate the performance of machine learning models. It is advantageous when you have limited data and want to...

Introduction to word embeddings Word embeddings have become a cornerstone of Natural Language Processing (NLP), transforming how machines process and understand human language. These vector...

What is fuzzy name matching? A fuzzy name matching algorithm, or approximate name matching, is a technique used to compare and match names with slight differences, variations, or errors. It is...

Graph Neural Network (GNN) is revolutionizing the field of machine learning by enabling effective modelling and analysis of structured data. Originally designed for graph-based data, GNNs have found...

What is few-shot learning? Few-shot learning is a machine learning technique that aims to train models to learn new tasks or recognise new classes of objects using only a small amount of labelled...

Why Combine Numerical Features And Text Features? Combining numerical and text features in machine learning models has become increasingly important in various applications, particularly natural...

L1 and L2 regularization are techniques commonly used in machine learning and statistical modelling to prevent overfitting and improve the generalization ability of a model. They are regularization...

What is hyperparameter tuning in machine learning? Hyperparameter tuning is critical to machine learning and deep learning model development. Machine learning algorithms typically have specific...

What is CountVectorizer in NLP? CountVectorizer is a text preprocessing technique commonly used in natural language processing (NLP) tasks for converting a collection of text documents into a...

The F1 score formula The F1 score is a metric commonly used to evaluate the performance of binary classification models. It is a measure of a model's accuracy, and it takes into account both...
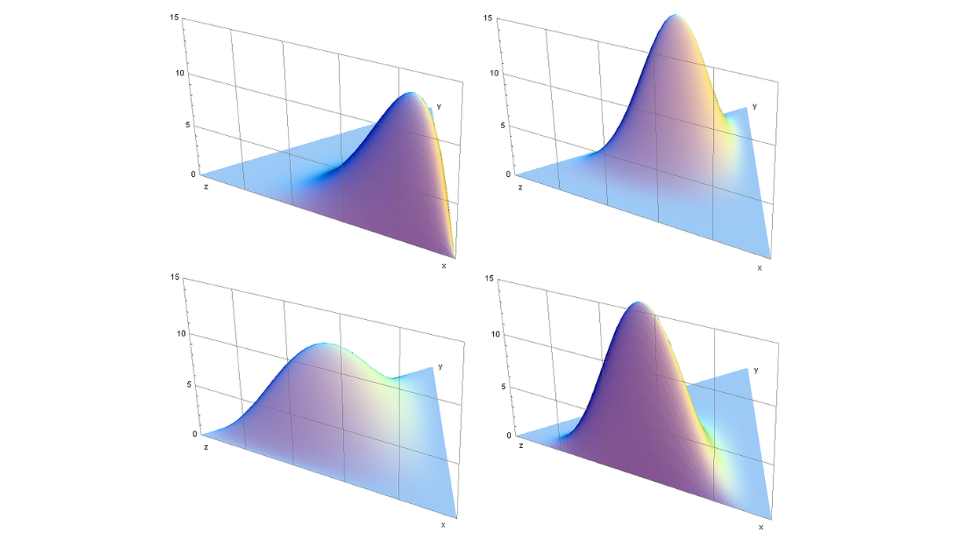
Latent Dirichlet Allocation explained Latent Dirichlet Allocation (LDA) is a statistical model used for topic modelling in natural language processing. It is a generative probabilistic model that...

What is GPT-3? GPT-3 (Generative Pre-trained Transformer 3) is a state-of-the-art language model developed by OpenAI, a leading artificial intelligence research organization. GPT-3 is a deep neural...
![How To Guide To Bias-Variance Trade-Off [2 Examples In Python: Polynomial Regression & SVM]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/04/bias-varince-trade-off.jpg?fit=960%2C540&ssl=1)
What are bias, variance and the bias-variance trade-off? The bias-variance trade-off is a fundamental concept in supervised machine learning that refers to the trade-off between the error due to...

In natural language processing, n-grams are a contiguous sequence of n items from a given sample of text or speech. These items can be characters, words, or other units of text, and they are used to...
![How To Implement Natural Language Processing (NLP) Feature Engineering In Python [8 Techniques]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/03/nlp-feature-engineering.jpg?fit=1200%2C675&ssl=1)
Natural Language Processing (NLP) feature engineering involves transforming raw textual data into numerical features that can be input into machine learning models. Feature engineering is a crucial...

Get a FREE PDF with expert predictions for 2026. How will natural language processing (NLP) impact businesses? What can we expect from the state-of-the-art models?
Find out this and more by subscribing* to our NLP newsletter.