What is a Content-Based Recommendation System? A content-based recommendation system is a sophisticated breed of algorithms designed to understand and cater to individual user preferences by...
![How To Build Content-Based Recommendation System Made Easy [Top 8 Algorithms & Python Tutorial]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/11/content-based-recommendation-system.jpg?fit=1200%2C675&ssl=1)
What is a Content-Based Recommendation System? A content-based recommendation system is a sophisticated breed of algorithms designed to understand and cater to individual user preferences by...
![How To Implement Inverted Indexing [Top 10 Tools & Future Trends]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/10/inverted-index.png?fit=1200%2C675&ssl=1)
Inverted index in information retrieval In the world of information retrieval and search technologies, inverted indexing is a fundamental concept pivotal in transforming a seemingly chaotic sea of...
![How To Implement Document Classification In Python [8 Machine Learning & Deep Learning Models]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/10/document-classification.png?fit=1200%2C675&ssl=1)
Basics of Document Classification Document classification, or document categorization, is a fundamental natural language processing (NLP) task that categorizes text documents into predefined...

What is document retrieval? Document retrieval is the process of retrieving specific documents or information from a database or a collection of documents. It's fundamental in information retrieval,...
![What Is Semantic Search & How To Implement [Python, BERT, Elasticsearch]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/10/semantic-search.jpg?fit=960%2C540&ssl=1)
What is semantic search? Semantic search is an advanced information retrieval technique that aims to improve the accuracy and relevance of search results by understanding the context and meaning of...

What is a Vector Space Model? The Vector Space Model (VSM) is a mathematical framework used in information retrieval and natural language processing (NLP) to represent and analyze textual data. It's...

What is Latent Semantic Analysis (LSA)? Latent Semantic Analysis (LSA) is used in natural language processing and information retrieval to analyze word relationships in a large text corpus. It is a...

What is fuzzy name matching? A fuzzy name matching algorithm, or approximate name matching, is a technique used to compare and match names with slight differences, variations, or errors. It is...
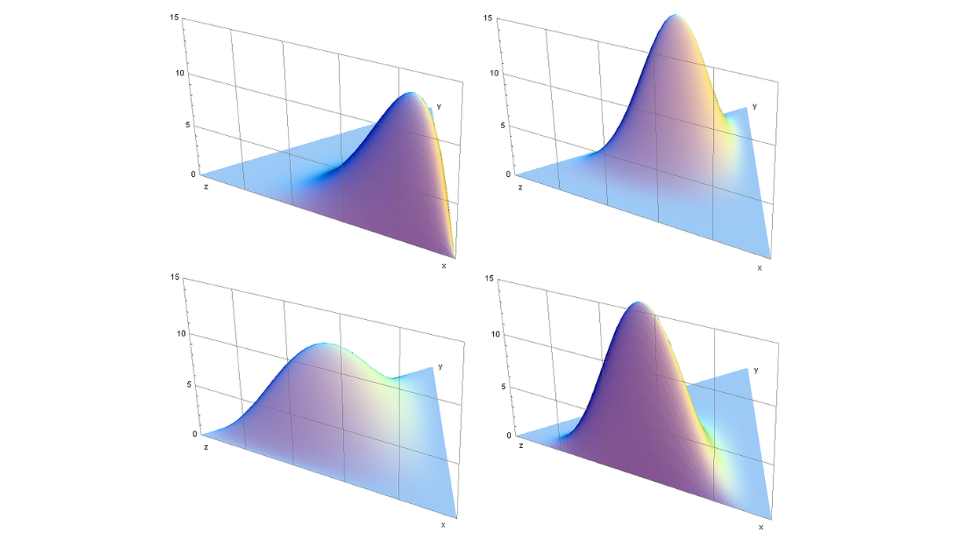
Latent Dirichlet Allocation explained Latent Dirichlet Allocation (LDA) is a statistical model used for topic modelling in natural language processing. It is a generative probabilistic model that...
![Tutorial TF-IDF vs Word2Vec For Text Classification [How To In Python With And Without CNN]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/02/word2vec-text-classification.jpg?fit=1024%2C576&ssl=1)
Word2Vec for text classification Word2Vec is a popular algorithm used for natural language processing and text classification. It is a neural network-based approach that learns distributed...

What is fuzzy logic? Fuzzy logic is a mathematical approach to reasoning about uncertain or vague information. Rather than the traditional binary true or false values found in classical logic, it is...

What exactly is text clustering? The process of grouping a collection of texts into clusters based on how similar their content is is known as text clustering. Text clustering combines related...

What is local sensitive hashing? A technique for performing a rough nearest neighbour search in high-dimensional spaces is called local sensitive hashing (LSH). It operates by mapping...

What is MinHash? MinHash is a technique for estimating the similarity between two sets. It was first introduced in information retrieval to evaluate the similarity between documents quickly. The...

What is SimHash? Simhash is a technique for generating a fixed-length "fingerprint" or "hash" of a variable-length input, such as a document or a piece of text. It is similar to a hash function and...
![How To Implement Fuzzy String Matching [4 Ways In Python]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/01/fuzzy-logic-hot-cold.jpg?fit=1024%2C1024&ssl=1)
This article discusses one of the most valuable tools when analysing textual data in natural language processing — fuzzy string matching. We first discuss what it is, its typical applications and...

Text similarity is a really useful natural language processing (NLP) tool. It allows you to find similar pieces of text and has many real-world use cases. This article discusses text similarity, its...

Get a FREE PDF with expert predictions for 2026. How will natural language processing (NLP) impact businesses? What can we expect from the state-of-the-art models?
Find out this and more by subscribing* to our NLP newsletter.