What is ensemble learning in machine learning? Ensemble learning is a machine learning technique that combines the predictions of multiple individual models to improve a machine learning algorithm's...

What is ensemble learning in machine learning? Ensemble learning is a machine learning technique that combines the predictions of multiple individual models to improve a machine learning algorithm's...
![Deep Dive into Active Learning in Machine Learning [How To In Python & PyTorch]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/08/active-learning-try-fail.jpg?fit=1200%2C675&ssl=1)
What is active learning in machine learning? Active learning is a machine learning technique that involves iteratively selecting and labelling the most informative examples from an unlabeled dataset...

Outlier detection in machine learning Outlier detection is a task in machine learning and data analysis involving identifying points that deviate significantly from the rest of the data. These data...

Welcome to our blog post, where we delve into a critical aspect of machine learning that often goes unnoticed but can significantly impact the reliability of our models - data leakage. As...
![Zero-shot Classification [Top 6 Models, How To Tutorial In Python & Alternatives]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/08/zero-shot-classification.jpg?fit=1200%2C675&ssl=1)
What is zero-shot classification? Zero-shot classification is a machine learning approach in which a model can classify data into multiple classes without any specific training examples for those...
![How To Apply Feature Scaling In Machine Learning [Top Methods & Tutorials In Python]](https://i0.wp.com/spotintelligence.com/wp-content/uploads/2023/07/min-max-feature-scaling.jpg?fit=1200%2C675&ssl=1)
What is feature scaling in machine learning? Feature scaling is a preprocessing technique used in machine learning and data analysis to bring all the input features to a similar scale. It is...

What is k-fold cross-validation? K-fold cross-validation is a popular technique used to evaluate the performance of machine learning models. It is advantageous when you have limited data and want to...

What is skip-gram? Skip-gram is a popular algorithm used in natural language processing (NLP), specifically in word embedding techniques. It is a method for learning word representations in a vector...

What is fuzzy name matching? A fuzzy name matching algorithm, or approximate name matching, is a technique used to compare and match names with slight differences, variations, or errors. It is...

Why Combine Numerical Features And Text Features? Combining numerical and text features in machine learning models has become increasingly important in various applications, particularly natural...

L1 and L2 regularization are techniques commonly used in machine learning and statistical modelling to prevent overfitting and improve the generalization ability of a model. They are regularization...

What is hyperparameter tuning in machine learning? Hyperparameter tuning is critical to machine learning and deep learning model development. Machine learning algorithms typically have specific...

What is CountVectorizer in NLP? CountVectorizer is a text preprocessing technique commonly used in natural language processing (NLP) tasks for converting a collection of text documents into a...

Unstructured data has become increasingly prevalent in today's digital age and differs from the more traditional structured data. With the exponential growth of information on the internet, the vast...

The F1 score formula The F1 score is a metric commonly used to evaluate the performance of binary classification models. It is a measure of a model's accuracy, and it takes into account both...

Classification vs regression are two of the most common types of machine learning problems. Classification involves predicting a categorical outcome, such as whether an email is spam or not, while...
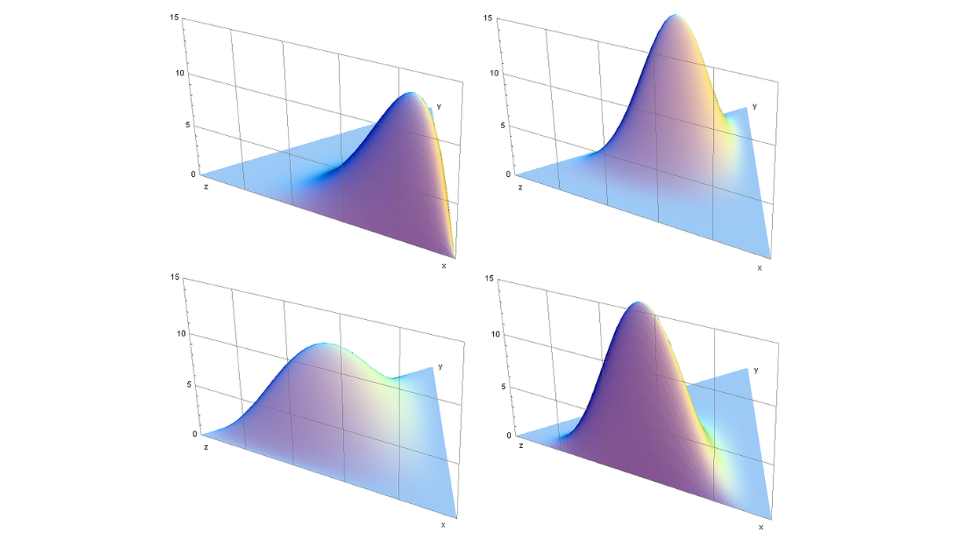
Latent Dirichlet Allocation explained Latent Dirichlet Allocation (LDA) is a statistical model used for topic modelling in natural language processing. It is a generative probabilistic model that...

Endogenous and exogenous variables are two important concepts. In machine learning, endogenous variables are the variables that are directly influenced by other variables within the system being...

Get a FREE PDF with expert predictions for 2026. How will natural language processing (NLP) impact businesses? What can we expect from the state-of-the-art models?
Find out this and more by subscribing* to our NLP newsletter.