What Are Vector Embeddings?
Imagine trying to explain to a computer that the words “cat” and “dog” are more similar to each other than to “car”. Computers don’t inherently understand language, images, or sounds the way humans do. They only understand numbers. This is where vector embeddings come in.
Table of Contents

At its core, a vector embedding is a way to represent any piece of data—words, sentences, images, or even sounds—as a numerical vector in a high-dimensional space. Each piece of data becomes a point in this space, and the location of that point captures the “meaning” or characteristics of the data.
Intuition Behind Embeddings
Think of an embedding as a map. On a city map, physically close places are likely related—you might find coffee shops clustered together. Similarly, in embedding space:
- Words or objects with similar meanings or features are close together.
- Items that are very different are far apart.

For example:
- The words “cat” and “dog” would appear close to each other.
- The word “car” would be farther away from both, reflecting its different context.
Why Use Vector Embeddings?
- Capture Relationships: Embeddings capture subtle similarities that simple keyword matching can’t.
- Enable Machine Learning: Most AI models work with numbers, so embeddings provide a bridge from raw data to algorithms.
- Support Advanced Applications: They power search engines, recommendation systems, natural language understanding, and even multimodal AI that combines text, images, and audio.

In short, embeddings transform complex, unstructured data into a format that machines can reason about, making them a cornerstone of modern AI.
How do Vector Embeddings Work?
Now that we understand what vector embeddings are, let’s dive into how they actually work. At a high level, embeddings are all about turning complex data into numbers that reflect the underlying relationships between items.
1. The Basics: Vectors and Distance
A vector is just a list of numbers. For example, a 3-dimensional vector could look like this:
[0.2, 0.9, 0.5]Vectors live in vector space, a mathematical space where each dimension represents a feature. In this space, the distance between vectors tells us how similar or different the items are:
- Euclidean distance: Straight-line distance between two points.
- Cosine similarity: Measures the angle between two vectors, focusing on direction rather than magnitude.

The closer two vectors are, the more similar the items they represent.
2. How Embeddings Are Learned
Embedding models learn the vectors by analysing patterns in the data. Some common approaches:
Word Embeddings (Word2Vec, GloVe, FastText):
Learn word meanings based on context. Words that appear in similar contexts have similar vectors.

Sentence Embeddings (BERT, Sentence-BERT):
Capture the meaning of whole sentences, not just individual words.
Example: “I love cats” and “Cats are amazing” will have vectors close together.
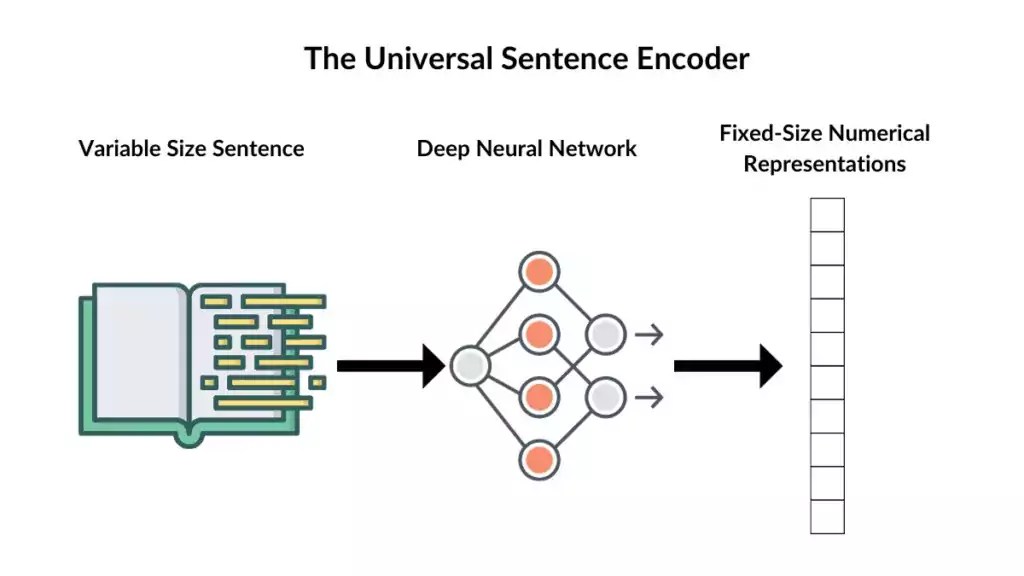
Image Embeddings (CNNs, CLIP):
Represent images as vectors by analysing patterns in pixels and extracting features.
Example: Photos of dogs will cluster together in embedding space, separate from cars.
3. Example: Words in Vector Space
Imagine a 2D representation of words:
- Cat: (0.2, 0.8)
- Dog: (0.3, 0.7)
- Car: (0.9, 0.1)
Here, “cat” and “dog” are close together, while “car” is far away. Even in hundreds of dimensions, this principle holds—the geometry of the space encodes meaning.
4. Putting It All Together
The magic of embeddings is that they encode relationships numerically, allowing algorithms to:
- Find similar items (semantic search, recommendations)
- Cluster items with similar properties
- Feed into machine learning models for classification, prediction, or generation
In short, embeddings turn raw data into a language that machines can mathematically reason about, opening the door to advanced AI applications.
Applications of Vector Embeddings
Vector embeddings aren’t just a theoretical concept—they’re the backbone of many AI systems we use every day. By representing data in a way that captures meaning and similarity, embeddings unlock a wide range of practical applications.
1. Natural Language Processing (NLP)
Embeddings allow machines to understand and compare text more intelligently than simple keyword matching.
- Semantic Search: Search engines can find documents based on meaning rather than exact words.
- Example: Searching for “best places to eat pizza” also retrieves results for “top pizza restaurants.”
- Chatbots & Virtual Assistants: Embeddings help match user questions to the most relevant answers.
- Text Classification: Spam detection, sentiment analysis, and topic modelling rely on embeddings to identify patterns in language.

2. Computer Vision
Images can also be represented as vectors, capturing visual features such as shapes, colours, and textures.
- Image Retrieval: Find images similar to a query image.
- Example: Upload a photo of a dog, and the system finds other dogs that look alike.
- Facial Recognition: Embeddings encode facial features to identify or verify individuals.
- Object Detection & Clustering: Grouping similar images for organisation or analysis.

3. Recommender Systems
Embeddings power recommendations by measuring similarity between items and users.
- Content-based Recommendations: Movies, books, or products are suggested based on similarity to items a user likes.
- Personalisation: User preferences can be represented as embeddings to provide tailored suggestions.

Example: If you enjoy sci-fi movies, embeddings enable the system to suggest similar sci-fi titles rather than random picks.
4. Multimodal AI and Beyond
Advanced AI systems combine embeddings from different data types: text, images, and audio.
- Multimodal Search: Query an image with text, or vice versa.
- Knowledge Graphs: Represent entities and their relationships in vector space for reasoning.
- Generative AI: Embeddings feed into models that generate text, images, or music based on semantic understanding.
Vector embeddings are like a universal translator for AI, turning complex, unstructured data into a numerical form that machines can understand and reason with. They make advanced AI applications—search, recommendation, recognition, and generation—not only possible but also scalable and effective.
Tools and Libraries for Embeddings
Now that we understand what embeddings are and how they work, let’s look at practical tools and libraries that make it easy to generate and use embeddings in real-world projects. Most of these tools are available in Python, the go-to language for AI and machine learning.
1. Hugging Face Transformers
The Transformers library provides pre-trained models for creating embeddings from text.
- Use case: Generate embeddings for sentences, paragraphs, or documents.
- Example: BERT, RoBERTa, and GPT-based models.
- Key advantage: Models are pre-trained on massive datasets, capturing rich semantic relationships.
Example:
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
sentence = "I love machine learning"
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1)
print(embedding)2. SentenceTransformers
A library built on top of Hugging Face for sentence-level embeddings.
- Simplifies semantic search, clustering, and similarity tasks.
- Pre-trained models make it easy to embed sentences with just a few lines of code.
Example:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["I love cats", "I love dogs"]
embeddings = model.encode(sentences)
print(embeddings)3. FAISS (Facebook AI Similarity Search)
A library for efficient similarity search and clustering of vectors, even in millions of dimensions.
Use case: Quickly find vectors most similar to a query vector.
Works seamlessly with embeddings from any model.
4. Other Popular Libraries
- Gensim: Word2Vec, FastText, and other classic embeddings.
- OpenAI Embeddings API: Access high-quality embeddings for text with minimal setup.
- TensorFlow & PyTorch: Frameworks for training custom embeddings from scratch.
Getting Started Tips
- Choose the right embedding model based on your task (word-level, sentence-level, image, multimodal).
- Normalise embeddings (e.g., unit vectors) for accurate similarity comparisons.
- Use indexing libraries like FAISS for large-scale similarity search.
- Experiment with pre-trained models before training your own—they often provide excellent results out-of-the-box.
Challenges and Considerations of Vector Embeddings
While vector embeddings are robust, they come with challenges and limitations that every practitioner should be aware of. Understanding these helps ensure embeddings are used effectively and responsibly.
1. High-Dimensional Spaces
Embeddings often exist in hundreds or thousands of dimensions, which can lead to the “curse of dimensionality.”
- Issue: In very high dimensions, distances between points can become less meaningful.
- Impact: Similarity comparisons may become less reliable, and computations more expensive.
- Mitigation: Techniques such as dimensionality reduction (PCA, UMAP, t-SNE) can help visualise or simplify embeddings.
2. Bias in Embeddings
Embeddings reflect the data they are trained on. If the training data contains biases, the embeddings will too.
- Example: Word embeddings trained on large text corpora might associate gender stereotypes with professions.
- Impact: Biased embeddings can propagate unfairness in AI systems (e.g., recommendation, hiring algorithms).
- Mitigation: Carefully select training data, evaluate for bias, and consider debiasing techniques.
3. Computational Costs
Generating, storing, and searching embeddings—especially at large scale—can be resource-intensive.
- Memory: Large embedding datasets can require gigabytes or terabytes of storage.
- Computation: Similarity searches over millions of vectors can be slow without indexing structures like FAISS.
- Mitigation: Use approximate nearest neighbour algorithms, cloud solutions, or batch processing to manage costs.
4. Context and Generalisation Limitations
Embeddings capture patterns present in training data, but may fail in edge cases or novel situations.
- Example: A model trained on English text might produce poor embeddings for slang, dialects, or other languages.
- Mitigation: Fine-tune embeddings on your specific domain or use multilingual/multimodal models where needed.
Key Takeaway
Vector embeddings are a powerful tool, but they are not magic. Being aware of high-dimensional issues, bias, computational constraints, and limitations in generalisation ensures your AI applications remain effective, fair, and efficient.
The Future of Vector Embeddings
Vector embeddings have already transformed AI, but their journey is far from over. Emerging research and technology trends indicate that even more powerful and versatile embeddings are on the horizon in the coming years.
1. Multimodal Embeddings
Traditionally, embeddings focus on a single data type—text, image, or audio. The future lies in multimodal embeddings, which combine multiple types of data into a single vector space.
Example: CLIP (by OpenAI) maps images and text into the same embedding space, allowing searches like “find images that match this caption.”
Impact: Enables richer AI understanding across modalities, such as combining vision, language, and audio in one system.
2. Integration with Large Language Models (LLMs)
Embeddings are increasingly integrated with LLMs to enhance reasoning, retrieval, and generation.
- Retrieval-Augmented Generation (RAG): Embeddings help LLMs retrieve relevant documents to generate more accurate answers.
- Personalisation: User preferences can be represented as embeddings, allowing LLMs to tailor responses.
- Scalability: Embeddings provide a structured way for LLMs to work with massive knowledge bases.

3. Knowledge Representation and Reasoning
Embeddings are being used to encode knowledge graphs, scientific data, and complex relationships in a vector space.
Example: Embedding entities and relations in research papers or databases enables AI to reason over connections that humans might miss.
Impact: Accelerates discovery in fields like medicine, finance, and cybersecurity.
4. Real-Time and Adaptive Embeddings
Future embeddings will be more dynamic and context-aware, adapting in real-time to changes in data or user behaviour.
Example: Recommendation systems could update embeddings on-the-fly as users interact with content.
Benefit: Creates AI systems that are more responsive, personalised, and accurate.
5. Democratisation and Accessibility
Open-source embedding models and cloud APIs are making embeddings accessible to everyone, not just AI researchers.
Anyone can now generate embeddings, build semantic search engines, or experiment with AI personalisation.
This trend is likely to accelerate innovation and practical applications across industries.
Vector embeddings are evolving from a technical trick to a foundational component of AI systems. As models become more sophisticated, embeddings will enable AI to understand, reason, and interact with the world in ways that were previously impossible. The future is not just about numbers—it’s about turning data into meaningful representations that machines can truly work with.
Conclusion
Vector embeddings have become a cornerstone of modern AI, transforming how machines understand and interact with the world. From representing words, images, and sounds as numerical vectors to powering search engines, recommendation systems, and AI assistants, embeddings turn complex data into something machines can reason about.
We’ve explored what embeddings are, how they work, and the vast array of applications they enable. We’ve also examined challenges—like high-dimensional spaces, bias, and computational costs—and looked ahead to the future, where multimodal, real-time, and context-aware embeddings promise even greater capabilities.
The key takeaway is simple: embeddings give AI a language for meaning. They allow machines to recognise patterns, measure similarity, and make informed decisions in ways that were impossible just a decade ago.
Whether you’re building a semantic search engine, a recommendation system, or experimenting with AI research, embeddings provide the foundation for more intelligent, more intuitive, and more capable AI systems.
Now it’s your turn—explore embeddings in your projects, experiment with pre-trained models, and see how this powerful tool can transform the way your systems understand data.












0 Comments